Today is #GivingTuesday, a global movement to kick off the charitable giving season.
![]()
When you buy a Raspberry Pi, you’re not only getting a fantastic little computer, but you’re also helping with our charitable educational mission to put the power of computing and digital making into the hands of people all over the world.
We’re also supported in other ways by very generous people and organizations who believe in what we do. They donate funds, staff time, products, and services to help us achieve our mission. We use all of these resources to give thousands of young people the opportunity to be empowered by technology.
![]()
At the end of last year, Uncle Sam granted us nonprofit status, which means we can accept tax-deductible donations from those of you who are in the United States! To celebrate the first-ever #GivingTuesday with US nonprofit status, we’re kicking off a crowdfunding campaign for Coolest Projects USA on the GlobalGiving platform. Your contribution will go towards our annual Coolest Projects event where we celebrate young people who create things with technology. And if you contribute between now and the end of the year, we’ll be eligible for bonus funds offered by GlobalGiving. Our goal is to raise $10,000 for Coolest Projects USA, and we need help from all of you!
Showcasing creativity at Coolest Projects North America
Coolest Projects is a world-leading showcase that enables and inspires the next generation of digital creators and innovators to present the projects that they created at their local CoderDojo, Code Club and Raspberry Jam. This year we brought Coolest Projects to the Discovery Cube Orange County for a spectacular regional event in California.
Those of you in the States can also support us by doing your holiday shopping with Amazon Smile or the 3,000 online stores on Giving Assistant. We’ll get a small contribution for your purchases, and that’ll go toward all the programs that support educators and youth in the United States.
![]()
If you would like to make a donation towards our work from anywhere in the world, you can do so via JustGiving or PayPal. Your support for the Raspberry Pi Foundation helps us to train educators face-to-face and online, to provide free educational content for everyone everywhere, to support over 10,000 free coding clubs around the world, to celebrate young creators at high-profile events, and much much more.
There are plenty of ways to help us achieve our mission all over the world:
No matter what you do, the most important thing we want you to know is how grateful we are to have you in the Raspberry Pi community — we deeply appreciate all of your support.
The post Support Raspberry Pi on #GivingTuesday appeared first on Raspberry Pi.
Highcharts is, in my opinion, one of the best JavaScript libraries to work with data visualization and charts out there. Even though Highcharts is open source, it’s a commercial library. It’s free for use in non-commercial applications though.
In this tutorial we are going to explore how to integrate it with a Django project to render dynamically generated charts. In relation to drawing the charts and rendering it to the client, all the hard work is done by Highcharts at the client side. The configuration and setup is pure JavaScript.
The main challenge here is on how to translate the data from your backend to a format that Highcharts will understand. This data may come from a database or an external API, and probably is represented as Python objects (like in a QuerySet), or simply be represented as Python dictionaries or lists.
Generally speaking, there are two ways to do it:
The first option is like a brute force and in many cases the easiest way. The second option requires a slightly complicated setup, but you will also benefit from the page loading speed and from the maintainability of the code.
Basically we just need to include the Highcharts library in our template and we are ready to go. You can either download and serve it locally or simply use their CDN:
<script src="https://code.highcharts.com/highcharts.src.js"></script>Now we need some data. I thought that it would be fun to play with an existing dataset. The Titanic dataset is pretty famous one, and easy to access.
What I did here was loading the dataset (1300~ rows) into a model named Passenger:
class Passenger(models.Model):
name = models.CharField()
sex = models.CharField()
survived = models.BooleanField()
age = models.FloatField()
ticket_class = models.PositiveSmallIntegerField()
embarked = models.CharField()If you are familiar with data mining, data science, or machine learning probably you already know this data set. This dataset is usually used for learning purpose. It’s composed by the list of passengers of the famous RMS Titanic tragedy.
We won’t be doing anything smart with it, just querying the database and displaying the data using Highcharts.
I won’t dive into deep details about Highcharts. The goal is to understand how to make Django and Highcharts talk. For details about how to do this or that with Highcharts, best thing is to consult the official documentation.
Here is a working example of a column chart using Highcharts:
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Django Highcharts Example</title>
</head>
<body>
<div id="container"></div>
<script src="https://code.highcharts.com/highcharts.src.js"></script>
<script>
Highcharts.chart('container', {
chart: {
type: 'column'
},
title: {
text: 'Historic World Population by Region'
},
xAxis: {
categories: ['Africa', 'America', 'Asia', 'Europe', 'Oceania']
},
series: [{
name: 'Year 1800',
data: [107, 31, 635, 203, 2]
}, {
name: 'Year 1900',
data: [133, 156, 947, 408, 6]
}, {
name: 'Year 2012',
data: [1052, 954, 4250, 740, 38]
}]
});
</script>
</body>
</html>The code above generates the following chart:
![]()
The basic structure here is:
Highcharts.chart('id_of_the_container', {
// dictionary of options/configuration
});The most straightforward way to do it is by writing directly in the template (which is not recommended).
Let’s write an query to display the number of survivors and deaths organized by ticket class.
views.py
from django.db.models import Count, Q
from django.shortcuts import render
from .models import Passenger
def ticket_class_view(request):
dataset = Passenger.objects \
.values('ticket_class') \
.annotate(survived_count=Count('ticket_class', filter=Q(survived=True)),
not_survived_count=Count('ticket_class', filter=Q(survived=False))) \
.order_by('ticket_class')
return render(request, 'ticket_class.html', {'dataset': dataset})The queryset above generates a data in the following format:
[
{'ticket_class': 1, 'survived_count': 200, 'not_survived_count': 123},
{'ticket_class': 2, 'survived_count': 119, 'not_survived_count': 158},
{'ticket_class': 3, 'survived_count': 181, 'not_survived_count': 528}
]Then we could just write it in the template, inside the JavaScript tags:
ticket_class.html
<div id="container"></div>
<script src="https://code.highcharts.com/highcharts.src.js"></script>
<script>
Highcharts.chart('container', {
chart: {
type: 'column'
},
title: {
text: 'Titanic Survivors by Ticket Class'
},
xAxis: {
categories: [
{% for entry in dataset %}'{{ entry.ticket_class }} Class'{% if not forloop.last %}, {% endif %}{% endfor %}
]
},
series: [{
name: 'Survived',
data: [
{% for entry in dataset %}{{ entry.survived_count }}{% if not forloop.last %}, {% endif %}{% endfor %}
],
color: 'green'
}, {
name: 'Not survived',
data: [
{% for entry in dataset %}{{ entry.not_survived_count }}{% if not forloop.last %}, {% endif %}{% endfor %}
],
color: 'red'
}]
});
</script>![]()
This kind of strategy is not really a good idea because the code is hard to read, hard to maintain and it is too easy
to shoot in the foot. Because we are using Python to generate JavaScript code, we have to format it properly.
For example, the code {% if not forloop.last %}, {% endif %} is to not append a comma (,) after
the last item of the array (otherwise the result would be [200, 119, 181,]). The newest JavaScript versions are
forgiving and accepts an extra comma (like Python does), but older versions don’t, so it might cause problem in old
browsers. Anyway, the point is you have to make sure your Python code is writing valid JavaScript code.
A slightly better way to do it would be processing the data a little bit more in the view:
views.py
import json
from django.db.models import Count, Q
from django.shortcuts import render
from .models import Passenger
def ticket_class_view_2(request):
dataset = Passenger.objects \
.values('ticket_class') \
.annotate(survived_count=Count('ticket_class', filter=Q(survived=True)),
not_survived_count=Count('ticket_class', filter=Q(survived=False))) \
.order_by('ticket_class')
categories = list()
survived_series = list()
not_survived_series = list()
for entry in dataset:
categories.append('%s Class' % entry['ticket_class'])
survived_series.append(entry['survived_count'])
not_survived_series.append(entry['not_survived_count'])
return render(request, 'ticket_class_2.html', {
'categories': json.dumps(categories),
'survived_series': json.dumps(survived_series),
'not_survived_series': json.dumps(not_survived_series)
})ticket_class_2.html
<div id="container"></div>
<script src="https://code.highcharts.com/highcharts.src.js"></script>
<script>
Highcharts.chart('container', {
chart: {
type: 'column'
},
title: {
text: 'Titanic Survivors by Ticket Class'
},
xAxis: {
categories: {{ categories|safe }}
},
series: [{
name: 'Survived',
data: {{ survived_series }},
color: 'green'
}, {
name: 'Not survived',
data: {{ not_survived_series }},
color: 'red'
}]
});
</script>Here’s what we are doing: first run through the queryset and create three separate lists, append the values and do the
formatting. After that, use the json module and dump the Python lists into JSON format. The result are Python strings
properly formatted as JSON data.
We have to use the safe template filter to properly render the categories because Django automatically escape
characters like ' and " for safety reason, so we have to instruct Django to trust and render it as it is.
We could also do all the configuration in the backend, like this:
views.py
import json
from django.db.models import Count, Q
from django.shortcuts import render
from .models import Passenger
def ticket_class_view_3(request):
dataset = Passenger.objects \
.values('ticket_class') \
.annotate(survived_count=Count('ticket_class', filter=Q(survived=True)),
not_survived_count=Count('ticket_class', filter=Q(survived=False))) \
.order_by('ticket_class')
categories = list()
survived_series_data = list()
not_survived_series_data = list()
for entry in dataset:
categories.append('%s Class' % entry['ticket_class'])
survived_series_data.append(entry['survived_count'])
not_survived_series_data.append(entry['not_survived_count'])
survived_series = {
'name': 'Survived',
'data': survived_series_data,
'color': 'green'
}
not_survived_series = {
'name': 'Survived',
'data': not_survived_series_data,
'color': 'red'
}
chart = {
'chart': {'type': 'column'},
'title': {'text': 'Titanic Survivors by Ticket Class'},
'xAxis': {'categories': categories},
'series': [survived_series, not_survived_series]
}
dump = json.dumps(chart)
return render(request, 'ticket_class_3.html', {'chart': dump})ticket_class_3.html
<div id="container"></div>
<script src="https://code.highcharts.com/highcharts.src.js"></script>
<script>
Highcharts.chart('container', {{ chart|safe }});
</script>As you can see, that way we move all the configuration to the server side. But we are still interacting with the JavaScript code directly.
Now this is how I usually like to work with Highcharts (or any other JavaScript library that interacts with the server).
The idea here is to render the chart using an asynchronous call, returning a JsonResponse from the server.
This time, we are going to need two routes:
urls.py
from django.urls import path
from passengers import views
urlpatterns = [
path('json-example/', views.json_example, name='json_example'),
path('json-example/data/', views.chart_data, name='chart_data'),
]The json_example URL route is pointing to a regular view, which will render the template which will invoke the
chart_data view. This call can be automatic upon page load, or it can be triggered by an action (a button click
for example).
views.py
def json_example(request):
return render(request, 'json_example.html')
def chart_data(request):
dataset = Passenger.objects \
.values('embarked') \
.exclude(embarked='') \
.annotate(total=Count('embarked')) \
.order_by('embarked')
port_display_name = dict()
for port_tuple in Passenger.PORT_CHOICES:
port_display_name[port_tuple[0]] = port_tuple[1]
chart = {
'chart': {'type': 'pie'},
'title': {'text': 'Titanic Survivors by Ticket Class'},
'series': [{
'name': 'Embarkation Port',
'data': list(map(lambda row: {'name': port_display_name[row['embarked']], 'y': row['total']}, dataset))
}]
}
return JsonResponse(chart)Here we can see the json_example is nothing special, just returning the json_example.html template, which we are
going to explore in a minute.
The chart_data is the one doing all the hard work. Here we have the database query and building the chart
dictionary. In the end we return the chart data as a JSON object.
json_example.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Django Highcharts Example</title>
</head>
<body>
<div id="container" data-url="{% url 'chart_data' %}"></div>
<script src="https://code.highcharts.com/highcharts.src.js"></script>
<script src="https://code.jquery.com/jquery-3.3.1.min.js"></script>
<script>
$.ajax({
url: $("#container").attr("data-url"),
dataType: 'json',
success: function (data) {
Highcharts.chart("container", data);
}
});
</script>
</body>
</html>Here is where the magic happens. The div with id container is where the chart is going to be rendered. Now, observe
that I included a custom attribute named data-url. Inside this attribute I stored the path to the view that will be
used to load the chart data.
Inside the ajax call, we make the request based on the URL provided in the data-url and instruct the ajax request
that we are expecting a JSON object in return (defined by the dataType). When the request completes, the JSON
response will be inside the data parameter in the success function. Finally, inside the success function, we
render the chart using the Highcharts API.
This is extremely useful because now we can decouple all the JavaScript from our template. In this example we used a single file for simplicity, but nothing stops us now from saving the script tag content in a separate file. This is great because we are no longer mixing the Django template language with JavaScript.
The result is the following screen shot:
![]()
In this tutorial we explored the basics on how to integrate Highcharts.js with Django. The implementation concepts used in this tutorial can be applied in other charts libraries such as Charts.js. The process should be very similar.
Whenever possible, try to avoid interacting with JavaScript code using the Django Template Language. Prefer returning the data as JSON objects already processed and ready to use.
Usually when working with charts and data visualization the most challenging part is to squeeze the data in the format required to render the chart. What I usually do is first create a static example hardcoding the data so I can have an idea about the data format. Next, I start creating the QuerySet using in the Python terminal. After I get it right, I finally write the view function.
If you want to learn more, the best way is to get your hands dirty. Here’s something you can do:
Le message commence par le genre d'information qui est susceptible de terrifier les adeptes du binge-watching.
The post Importante campagne de phishing usurpant l’identité de Netflix, la FTC émet une alerte appeared first on WeLiveSecurity
Se doter d’un mot de passe solide représente un bon début, mais il y a d'autres façons de vous assurer que votre courriel est aussi sécuritaire que possible.
The post La sécurité du courrier électronique : au-delà de votre mot de passe appeared first on WeLiveSecurity
Les escroqueries par le biais d'applications et de sites de rencontre en ligne sont un phénomène qui fait de nombreuses victimes dans le monde entier. Quelques exemples récents à travers le globe.
The post Quand l’amour tourne au cauchemar : escroqueries sur les applications et les sites de rencontre en ligne appeared first on WeLiveSecurity
Au lieu d'un gain financier ou d'autres objectifs, plus habituels, un attaquant opte pour la politique de la terre numérique brûlée.
The post L’attaque d’un fournisseur de messagerie cause la suppression de près de deux décennies de données appeared first on WeLiveSecurity
Entretien avec Lukáš Štefanko, chercheur en logiciels malveillants d'ESET, au sujet des logiciels malveillants bancaires ciblant Android desquels traitent de son dernier white paper.
The post Naviguer dans les eaux troubles des logiciels malveillants bancaires Android appeared first on WeLiveSecurity
Au coût financier de ces fraudes, nous devons ajouter chagrin d'amour vécu par les dizaines de milliers de personnes qui tombent dans les escroqueries romantiques chaque année.
The post Quel est le coût réel des arnaques romantiques? appeared first on WeLiveSecurity
Le premier concert virtuel à se dérouler dans un jeu vidéo a suscité l'intérêt non seulement des joueurs, mais aussi d’escrocs, qui ont tenté de profiter de cet événement d’envergure en incitant les utilisateurs à acheter des billets, alors que ce concert était gratuit.
The post Concert de DJ Marshmello sur Fortnite : Un événement emblématique attirant aussi les arnaqueurs appeared first on WeLiveSecurity
Le constructeur d'automobiles électriques travaille sur un correctif pour cette vulnérabilité, qui devrait être résolue d’ici quelques jours
The post Deux hackers éthiques piratent une voiture Tesla et la gardent appeared first on WeLiveSecurity
Cette semaine c’est l’Open Access Week. Pour marquer l’occasion, de nombreuses ressources sont publiées (#teasing : reviendez demain pour une nouveauté de et par Pierre-Carl ![]() ).
).
Parmi ces ressources, figshare a édité une compilation d’articles traitant des données ouvertes dans le domaine de la recherche scientifique. Pour rappel, figshare est la première plate-forme au monde à proposer la publication de jeux de données issus d’expérimentation scientifique ainsi que des figures et autres supports n’ayant pas trouvé de place dans un article scientifique « officiel ». Séquence émotion pour votre serviteure qui était en thèse au même moment que Mark, le fondateur de figshare, avec qui on avait organisé une compétition de blogs scientifiques et co-écrit la toute première FAQ de figshare.
Mais revenons à nos moutons. Le rapport de figshare, intitulé The State of Open Data, est une sélection de divers papiers de recherche écrits par des scientifiques de différentes universités, de représentants associatifs et d’experts du secteur privé. Le sujet est assez vaste et parle des données ouvertes en général, même si les données de la recherche y ont une place notable. N’y cherchez pas par contre de participation française…
Deux articles présentent les conclusions du questionnaire adressé à la communauté scientifique par figshare. Le questionnaire a recueilli les réponses d’environ 2 000 personnes. Les données brutes anonymisées sont disponibles sur figshare. J’en ai utilisé pour illustrer certains points de la discussion.
Deux grandes dimensions ressortent des réponses : les défis structurels et ceux liés à la culture de l’ouverture de la recherche. Cette dernière englobe les questions « classiques » du genre « mais pourquoi devrais-je ouvrir mes données alors que mes collègues n’en font rien ? », « est-ce que mes concurrents vont utiliser mes données pour me devancer dans la publication et donc, avoir les financements pour lesquels je rempile ? » ou encore « peut-on se rendre compte que j’ai un peu exagéré les résultats obtenus ? ». La question de la reconnaissance des efforts individuels d’ouverture des données revient à différents endroits dans le rapport et notamment dans l’article de David Groenewegen (directeur de recherche à l’université Monash, Australie ; pp. 34-36). Ces questionnements sont « humains », pour reprendre le qualificatif des auteurs, mais je ne m’y attarderai pas.
La dimension structurelle qui émerge de ce questionnaire est discutée en de plus amples détails. Elle englobe des questionnements plus pratiques tels que « qu’est-ce que je dois faire pour ouvrir mes données ? », « quel(s) est(sont) le(s) bon(s) format(s) ? », « ai-je la permission de mon agence de financement de partager les données de mes recherches ? » ou encore « partager OK, mais n’est-ce pas du travail supplémentaire pour moi et qui ne reçoit aucune reconnaissance ? ».
Les réponses recueillies permettent de dresser un état des lieux de la connaissance et l’utilisation des données ouvertes en recherche. Bien évidemment, la méthodo peut être critiquée, mais les observations que l’on peut faire ont un intérêt qualitatif et méritent d’être soulignées.




Et parlant de recherche et d’obtention de financements, le monstre des citations s’impose. Les réponses sont assez intéressantes ici :

De manière assez surprenante quand même, les interrogés avouent ne pas toujours bien savoir comment citer les jeux de données réutilisés.
Au-delà des observations autour des pratiques, on peut également tirer quelques conclusions supplémentaires également intéressantes :


La question des licences est loin d’être anodine. Je vous recommande vivement la lecture de cette brève “twitterstorm” de John Wilbanks, anciennement à l’origine de Science Commons (l’initiative liée à la science chez Creative Commons) et aujourd’hui, l’un des piliers de Sagebio. Il souligne la complexité inhérente de la notion de propriété intellectuelle et son rapport peu amène avec l’objet “données” :
Ces observations font donc ressortir l’importance de trois éléments structurels du processus par lequel on rend publiques des données issues de la recherche scientifique :
Dr Sabina Leonelli (University of Exeter, Royaume-Uni, pp. 7-12) met l’accent sur l’impact des données ouvertes sur l’économie et la politique de la recherche tel que l’on peut le penser à partir des conceptions que l’on a des données scientifiques :
Que la recherche soit mue par des données plutôt que par des théories, des hypothèses, des modèles ou des changements de politiques publiques reste un sujet de débat. Ce qui est clair [cependant], c’est que les données sont de plus en plus conceptualisées comme des produits dont la valeur est inhérente à la recherche scientifique, plutôt que comme des composantes du processus de recherche qui n’ont pas de valeur propre.
Elle ajoute que les réutilisations que l’on peut faire de ces données ne ressemblent pas toujours celles que l’on fait traditionnellement des publications scientifiques. Ainsi, il est important de bien analyser pourquoi le mouvement en faveur des données ouvertes est devenu aussi populaire dans le discours scientifique et politique contemporain. Pour ce faire, elle propose d’articuler la réflexion autour des quatre dimensions suivantes :
Pour rebondir sur les considérations sociétales et culturelles et la valeur des données de recherche, l’article de Prof. Daniel Paul O’Donnell (université Lethbridge, Canada ; pp.38-40) sur les changements induits par les données ouvertes dans les sciences humaines est intéressant. Il y élabore le changement de pratique et la redéfinition des objets d’étude en SHS, dans une veine sensiblement épistémologique. En effet, la tradition veut que les chercheurs en SHS travaillent sur des détails provenant d’un corpus réduit lesquels permettent de construire une argumentation plus générale et généralisable. Comme il le remarque avec un certain amusement, « à l’ère de l’open data, on peut être tenté de voir cette démarche comme une analyse d’un petit échantillon sans puissance statistique ». Mais une telle critique constituerait « une sorte d’erreur catégorielle », comme il dit. En effet, la recherche SHS diffère de celle dans les sciences dites « dures » par sa finalité : les premières visent à l’interprétation alors que les dernières cherchent des solutions. Ainsi, conclut-il :
[l]e véritable défi pour les sciences humaines à l’ère des données ouvertes numériques est de reconnaître la valeur des deux types de sources, à savoir le matériau que nous pouvons générer avec des algorithmes à des échelles autrefois impensables et la valeur toujours actuelle du passage originel.
Enfin, diverses participations proposent des approches permettant d’accélérer les activités de plaidoirie et de sensibilisation autour de l’ouverture des données de recherche. Je vous laisse les découvrir et, qui sait, vous en inspirer !
Je diffuse aujourd’hui mon principal projet de ces derniers mois, qui marque également l’aboutissement d’une réflexion engagée depuis plusieurs années sur Sciences communes : une étude critique sur les nouveaux modes d’éditorialisation des revues scientifiques en accès ouvert réalisée pour BSN — et très opportunément, cela tombe en pleine Open Access Week…
![]()
L’étude n’est que la version « synthétique » d’une quarantaine de pages d’un ouvrage qui paraîtra dans quelques mois. On peut retrouver également certains éléments propres à l’ouvrage (non repris dans l’étude) dans la présentation que j’en ai tirée pour la BSN et que j’ai ressorti la semaine dernière pour le séminaire PragmaTIC :
Le libre accès connaît aujourd’hui un tournant majeur. Il entre dans la loi : la Loi pour une République numérique prévoit un droit de republication des versions auteur ainsi qu’une exception au droit d’auteur pour faire de l’extraction automatisée de textes et de données (text & data mining, encore connu sous le sigle TDM). Au-delà de cette officialisation, le libre accès, sous toutes ses formes (archives ouvertes, revues, bases de données) est devenu un phénomène massif et incontournable, toutes disciplines, communautés et pays confondus.
La mise à disposition gratuite, voire sous licence libre, dissimule des choix éditoriaux, économiques et même politiques, radicalement distincts. Une partie du mouvement du libre accès est ainsi tentée par une mutation a minima : le journal flipping, soit une reconversion (to flip) des budgets consacrés aux abonnements en achats de « droits à publier » en libre accès, sans rien changer aux montants.
Cette reconversion maintient en l’état l’oligopole des géants de l’édition scientifique (bien présenté dans le dernier Datagueule), voire en étend la portée. Car un acteur comme Elsevier n’attend pas la généralisation du libre accès pour amorcer sa reconversion. Les acquisitions successives de Mendeley ou de l’archive ouverte SSRN (en attendant, peut-être, celles de ResearchGate ou Academia) témoignent de l’avènement de formes de contrôle et de captation inédites de l’activité scientifique : les interactions des chercheurs autour de leur publication alimentant un vaste recueil de métriques, revendues entre autres aux institutions universitaires. Nous assistons à l’émergence d’un nouveau modèle économique de l’édition scientifique assez largement inspiré de celui des grandes industries du web comme Facebook ou Google.
D’autres modèles existent : de par son ampleur-même, la conversion au libre accès autorise une réforme plus globale des conditions de diffusion de l’écrit scientifique. Les évolutions sont déjà engagées. C’est ce que rend visible la « cartographie » des pratiques et des initiatives émergentes qui se décline sur les quatre parties du rapport : outils d’édition, formes d’écritures, dispositifs d’évaluations et modèles économiques connaissent des transformations parfois radicales — et parfois convergentes. L’article n’est plus seulement ce un objet fixe et immuable une fois le processus de publication achevé mais connaît une multitude d’incarnation ultérieures (par exemple en se métamorphosant en données grâce aux techniques de text & data mining). L’évaluation ne s’arrête pas davantage au seuil de la revue : en s’ouvrant (open peer review), elle prend la forme d’une réception continue.

En 2016, la question n’est plus tant de susciter ou de développer des innovations, mais de les intégrer et de les combiner dans des infrastructures cohérentes. L’architecture du web permet de faire cohabiter et « dialoguer » des modèles très différents par le biais de standards communs. Pour soutenir cette « bibliodiversité », il est nécessaire de la donner à lire, de faciliter la circulation d’une forme à l’autre et d’une plateforme à l’autre. J’ai ainsi proposé une petite projection (connus par les initiés de BSN sous le nom de code de « slide 63 ») du rôle déterminant que pourraient désormais jouer les archives ouvertes au-delà du simple recueil de l’article en recensant la pluralité de ces incarnations : évaluations, réplications, extraction de données…

L’élaboration des infrastructures ne soulève pas des enjeux que « techniques ». Finalement un acteur comme Elsevier pourrait très bien jouer ce rôle (et commence à le faire). La différenciation s’opère sur un autre plan : celui, « politique », de la gouvernance. L’enjeu double est aussi bien d’empêcher le détournement de l’open access au profit de nouvelles enclosures que de développer des processus de prise décision plus efficaces et mieux adaptés à un contexte fortement évolutif. Le futur de l’édition scientifique passe ainsi peut-être par l’avènement de grandes plateformes auto-gérées. Celles-ci s’inscriraient la lignée de communs numériques comme Wikipédia ou OpenStreetMap, mais avec des modèles forcément différents, qui restent encore à inventer.
Bien qu’il m’ait été officiellement confié en janvier dernier, le rapport a été « préparé » depuis trois ans sur Sciences Communes. Le présent carnet a été créé en 2013 dans la perspective d’étudier et de référencer les « les nouvelles pratiques de réutilisation des publications et des données scientifiques ». Le rapport va aujourd’hui beaucoup plus loin que ce que j’imaginais alors : j’étais alors plutôt focalisé sur les questions de licences, tout en ayant en tête la perspective d’un écosystème élargi, né de la mobilité inédite des textes et données de la recherche (mon rapport particulier à l’open access, découvert alors que j’étais un simple contributeur sur Wikipédia dans l’incapacité d’accéder aux grandes bases d’articles sous paywall, n’y est pas étranger). Les dimensions de la « cartographie » du rapport sont en partie apparues dans le fil de ce carnet : la possibilité d’une captation de l’open access par des industries académiques 2.0, la nécessité d’une réponse politique, la longue « préhistoire » du libre accès…
Il y a une autre forme de continuité. Dans le rapport comme dans Sciences communes, les opportunités ouvertes par les nouvelles méthodes et formes d’écriture scientifique ne sont pas juste signalées mais mises en pratiques et exploitées. J’ai ainsi repris des données déposées sur Figshare ou Zenodo et j’ai développé des programmes d’extractions automatisés d’articles scientifiques (notamment pour situer le débat académique sur le terme d’open peer review) — tout comme, j’ai pu, par le passé, publier ici des « expériences » (1, 2, 3) qui démontraient, par l’exemple, l’opportunité de penser la publication scientifique comme une production croisée de textes, de données, de codes et de visualisations.

Et puis, ce travail est une forme de production collaborative par procuration. Si j’en suis techniquement le rédacteur, je ne peux pas laisser de côté toutes les influences, déterminantes, qu’il laisse percevoir : celles de mes « encadrants » (Serge Bauin, Emmanuelle Corne, Jacques Lafait et Pierre Mounier), celle de ma collaboratrice sur Sciences Communes Rayna Stamboliyska (qui a directement contribué à l’écriture de ce présent billet), celle de mes collègues de SavoirsCom1 (Lionel Maurel, Thelonious Moon, Mélanie Dulong de Rosnay — également contributrice sur Sciences Communes) et de tant d’autres, théoriciens ou acteurs du libre accès (Marin Dacos, Daniel Bourrion, Guillaume Cabanac, Marie Farge…)
[Analyse écrite à quatre mains]
Le 1er février, Le Monde lançait en fanfare un outil de vérification de l’information, Decodex. Dix jours plus tard, une adresse IP du journal s’est retrouvée bloquée pendant neuf mois sur Wikipédia pour… avoir introduit de fausses informations sur l’encyclopédie libre. Le journaliste scientifique du Monde, Pierre Barthélémy, a en effet créé (et laissé en place pendant plusieurs semaines) un article presque entièrement faux, consacré à un philosophe grec méconnu, Léophane. Le but de Pierre Barthélémy : faire “une expérience pour un article sur la vérifiabilité des infos sur Internet à l’heure des fake news”.
Quel lien entre la controverse autour de Decodex et les agissements de P. Barthélémy ? Certes ces deux événements ne sont pas directement liées. Mais les deux s’inscrivent dans un contexte particulier : le sentiment d’évoluer dans une « ère post-vérité » où l’exactitude des informations est sans importance et où toutes les sources se valent quelles que soient leurs approches de qualité des informations. Le point de départ de Decodex — aider les lecteurs du Monde à “se repérer face à une vague toujours plus forte de fausses informations” — et la prétendue exploration de P. Barthélémy semblent ainsi complémentaires. Nous ne commenterons pas ici la démarche de Decodex.
Nous avons demandé un droit de réponse au Monde spécifiquement après la publication d’un article par P. Barthélémy où il détaille son approche. Notre positionnement est multiple : scientifiques, éditorialistes et contributeurs à Wikipédia, nous identifions de graves problèmes dans la démarche de P. Barthélémy. Ces manquements sont aussi bien en amont qu’en aval de la publication de son article. La gravité des faits commis par P. Barthélémy et le manque apparent d’évaluation de l’impact de ses agissements s’ajoutent à l’outrage qui est le nôtre et celui de collègues, constaté à travers diverses discussions ces derniers jours.
On lit dans son article que P. Barthélémy place clairement sa démarche sous des auspices politiques : “L’idée m’est venue à l’automne dernier, lors de la campagne présidentielle américaine, marquée du sceau de la « post-vérité » et des « fake news ».” En décembre 2016, le journaliste crée donc une entrée sur Léophane. Il s’agit d’un obscur philosophe grec ayant véritablement existé. Pourtant, la page sur Léophane contient un mélange d’informations vraies et inventées. Barthélémy imagine que le personnage élabore une “méthode thérapeutique fondée sur les couleurs” et décède de l’épidémie de peste d’Athènes. Il s’appuie par contre sur une des meilleures estimations de sa chronologie (naissance en -470 et décès en 430 av. J-C) et relaie en détail sa contribution la mieux documentée à l’histoire naturelle (la détermination du sexe de l’enfant par la position des testicules).
Même pour un connaisseur, ce mélange faux-vrai est difficile à dénouer. Les sources antiques et les études modernes sur Léophane sont très limitées. De l’aveu d’un spécialiste, Lorenzo Perilli, “il est ignoré dans tous les ouvrages de référence que j’ai pu consulter”. Seule la consultation des sources apportées par Barthélémy aurait permis de “falsifier” ses contributions. Or, elles ne sont pas en libre accès : contributeurs bénévoles, les wikipédiens n’ont généralement pas accès aux revues ou aux publications sous paywall, diffusées à des tarifs prohibitifs.
En outre et de manière à rendre son canular encore plus ressemblant à la vérité, P. Barthélémy introduit des références à Léophane sur des articles Wikipédia mieux exposés (Hippocrate, Théophraste). Ces liens sont censés servir de preuves de la véracité du Léophane tel que narré par P. Barthélémy.
On est ainsi face à la création délibérée de fausses informations et le vandalisme de diverses ressources sur l’encyclopédie en ligne. Si l’on y regarde de plus près, une telle démarche est irrespectueuse quant au travail entièrement bénévole des modérateurs, administrateurs et contributeurs de Wikipédia. Ceux-là ont ainsi raison de se sentir dénigrés et pris pour des “rats de laboratoire”. La démarche de P. Barthélémy est d’autant plus incompréhensible qu’elle émane d’un compte utilisateur “jetable” (Pomlk2) et de plusieurs adresses IP : toutes les éditions sont donc faites anonymement, même s’il est très facile d’identifier à quelle institution appartient l’adresse. Si un tel anonymat peut être évoqué pour mimer une prétendue démarche de “fausseur”, on ne comprend pas pourquoi l’équipe de modération Wikipédia n’est pas informée. Par conséquent, l’une des adresses IP utilisées par P. Barthélémy, appartenant aux adresses du Monde, est bloquée pour neuf mois pour vandalisme. Bel exploit.
Mais si ces éléments sont, somme toute, secondaires, arrêtons nous aux véritables problèmes :
7/ @PasseurSciences : pour un canular réussi (et il en a existé), il faut : un objectif, un objet d’études, une méthode. Rien de tout ça ici
— Alexandre Moatti (@A_Moatti) 13 février 2017
Quel est le lien avec les “fake news” et l’élection américaine ? Quelle méthodologie sous-tendant cette “expérience” ? Et quid de l’éthique ? Souvenez-vous, aussi bien les scientifiques que les journalistes en ont une : alors, on s’attendrait à ce que P. Barthélémy fasse preuve d’un excès de précautions et d’une rigueur exemplaire. Malheureusement, il n’en est rien.
Puisque P. Barthélémy parle d’“expérience” et tente de se placer dans la position de celui qui crée du savoir précédemment inexistant, sa démarche peut être assimilée à celle d’un chercheur. Regardons-y avec les yeux de chercheur donc. Ce dernier a une approche (appelée hypothético-déductive) ordonnée et cadrée consistant à formuler des hypothèses sur le comportement d’un système et de développer des expériences permettant de valider l’une de ces hypothèses. Une hypothèse n’est pas une idée volatile qui nous passe par la tête et face à laquelle on reste dans un étonnement béat. Une hypothèse provient d’un comportement du système inhabituel. Mais pour savoir ce qui est inhabituel, on doit avoir une excellente connaissance préalable dudit système. Ce n’est qu’en ayant une démarche méthodologique, rigoureuse et qui s’inscrit dans un contexte de recherches que l’on peut véritablement tirer des conclusions sur l’impact de nos trouvailles.
Or, l’approche de P. Barthélémy n’a aucune de ces caractéristiques fondamentales. Elle émane d’une idée dans l’air du temps, en réaction à une conjoncture. Il n’y a ni hypothèse formulée (ou alors P. Barthélémy ne le dit pas clairement), ni connaissance poussée de l’écosystème Wikipédia. Les contributeurs et contributrices de Wikipédia, soit vous, nous, ne sont pas des capricieux qui s’arc-boutent dès que quelqu’un leur dit un mot de travers. Au contraire, il s’agit de personnes de richesses culturelles et de curiosité qui font de leur mieux et bénévolement pour cultiver le jardin qu’est l’encyclopédie libre Wikipédia. Promenez-vous sur les pages de discussions, vous verrez que ces bénévoles sont les premiers à débattre de la fiabilité, des processus pour assurer cette dernière et de pinailler parfois à l’usure pour que chaque phrase soit correcte et sourcée. Ainsi, chaque modification peut être suivie publiquement.
C’est faire fi de cet écosystème ouvert que de s’engager dans le vandalisme que P. Barthélémy a commis. Si P. Barthélémy connaissait un peu mieux la communauté et le fonctionnement de Wikipédia, il y aurait probablement réfléchi à deux fois avant de retweeter les invectives contre Wikipédia d’un ex-contributeur, banni pour plusieurs infractions, et s’exprimant en soutien aux agissements de P. Barthélémy. C’est également mal connaître les indicateurs dudit système, soit les possibilités de pouvoir conclure quoi que ce soit de cette “expérience” :
P. Barthélémy indique que « plusieurs dizaines de personnes sont venues lire l’histoire de Léophane ». Il n’invoque aucune source à l’appui de cette estimation. D’après l’outil de Wikipédia traquant les vues,, il y aurait 172 consultations entre la création de l’article le 30 décembre 2016 et la révélation du canular.
Le nombre de lecteurs réels est bien inférieur. Très soucieuse du respect de la vie privée des utilisateurs, la Wikimédia Foundation ne donne aucune estimation du nombre de visiteurs uniques. Chaque contribution sur l’article (24 au total avant la suppression) correspond potentiellement à plusieurs pages vues (une pour la modification, une pour la sauvegarde,…). Le nombre de consultations se trouve ainsi étroitement corrélé au nombre de contributions tel que consigné dans l’historique :

Les 172 consultations incluent également des lecteurs non humains. Depuis 2015, le site distingue les robots sous réserve qu’ils se présentent comme tel (en l’indiquant dans leur “carte d’identité”, appelée user agent). Mais rien n’empêche un robot de falsifier son identité. Le nombre de lecteurs réels, qui ne se sont pas limités à survoler la page, est ainsi très faible et Pierre Barthélémy ne sait rien sur eux. Il n’a ainsi aucune donnée sur le profil socio-démographique des visiteurs de la page, sur les manières d’arriver là, ce qu’ils ont retenu de l’article,… Par contraste, les études scientifiques sur la réception des contenus médiatiques ou scientifiques font fréquemment appel à des échantillons contrôlés et parviennent ainsi à analyser précisément les modes de lectures (au-delà du “mince ils se sont trompés”).
Enfin, pour qu’un canular soit efficace, il faut qu’il ait été repris. Quelles métriques, quelles preuves avons-nous que ce soit le cas ? (On vous aide : aucune.)
Usuellement on compare un comportement (diffusion de fake) à un autre (diffusion de non-fake). Les études scientifiques de la fiabilité de Wikipédia font ainsi fréquemment appel à des évaluations croisées avec des encyclopédies généralistes (comme Britannica) ou spécialisées et parviennent ainsi à établir relativement la qualité de Wikipédia selon plusieurs critères (part des erreurs factuelles, actualisation, complétude,…)
Dans l’approche de P. Barthélémy, il n’y a rien de tel. Il n’y a rien non plus quant au véhicule de cette diffusion (il parle seulement de Wikipédia et non pas de Wikipédia par rapport à d’autres sources). Toute personne qui a un jour tenté de définir l’impact et la causalité de deux actions connaît la difficulté quasi-insurmontable de la tâche. Ajouter le manque total de métriques prédéfinies pour rendre compte de cet aspect et voilà que cette observation mène (de nouveau) nulle part.
Si l’on admet que son “expérience” serait menée à terme sans être découverte, en quoi un seul cas permet d’extrapoler sur des dérives générales ? Au mieux, on aurait eu affaire à un mauvais article, au pire les conclusions de l’“expérience” seraient une autre forme de fake news en indiquant que toutes les observations se valent quelle que soit leur qualité. Et ne parlons même pas de la dérive potentielle d’une situation où un tel fait unique serait présenté comme résultant d’une démarche scientifique : cela s’appelle un argument d’autorité et son utilisation en sciences n’est pas appréciée.
Les facteurs influençant le comportement d’un système ne peuvent en aucun cas être considérés comme la figure de Dieu dans l’Ancien Testament : ça vous [tue/guérit/informe/rayer la mention inutile] en fonction du degré de foi que vous y attachez. La science et la foi sont deux choses distinctes, en science on ne choisit pas à la carte quelle donnée/quel fait prendre en compte. Mais dans le cadre d’un désert informationnel en matière de science, on ne peut pas combler ce vide d’actes de foi ou de désinformation. Parler de science, c’est parler également de sa technicité inhérente. Oui, c’est parfois chiant. Et oui, c’est également requis.
En conclusion donc, cette “expérience” a montré que n’importe qui, même un journaliste scientifique, peut aller sur un site web à édition ouverte et y introduire de fausses informations. Totalement novateur.
On pourrait vous sortir plein d’adages plus ou moins pontifiants. Ils pointeraient toujours vers le même problème : la démarche entreprise par P. Barthélémy semble faite sans aucune éthique. Voici les manquement éthiques que nous avons constatés, nous fondant aussi bien sur notre formation scientifique que sur les échanges avec des collègues. Des échanges que P. Barthélémy aurait des difficultés à ignorer, mais qui ont cependant été totalement occultés de son article :
Il y a un abus de confiance de la communauté des contributeurs Wikipédia. P. Barthélémy s’est longuement entretenu avec deux des administrateurs de Wikipédia en français et, malgré l’assurance de ses bonnes intentions, les actes en disent autrement. Ainsi, initialement P. Barthélémy parlait d’“une expérience […] sur la vérifiabilité des infos sur Internet à l’heure des fake news” ; lors de son échange avec Jules, admin Wikipédia : “[l]e but (« avoué ») de l’expérience était de mettre en lumière les limites de l’encyclopédie”. Finalement, avec la publication de l’article de P. Barthélémy, on lit un appel de “mise en quarantaine” a priori des contributions.
Cette transformation pose de nombreux problèmes : il s’agit de création avouée et élaborée de fausses informations et de vandalisme de pages pré-existantes mais aussi de non-prise en compte de l’historique de ce genre de débats. Cette mise en quarantaine a déjà fait débat et ce de nombreuses fois… depuis 2007 : sa mise en œuvre sur la Wikipédia Germanophone débouche sur des délais d’attentes considérables (deux semaines pour approuver une contribution) et a probablement contribué au déclin significatif de la participation depuis son activation en 2008. Un sondage proposant la mise en place d’un système similaire sur la Wikipédia francophone avait été très largement rejeté en 2009 (78% d’opposition), notamment sur la base de ces résultats empiriques. Par ailleurs, les réponses au tweet de P. Barthélémy sur la question sont sans exception en opposition.
Quelle était la finalité réelle de cette manipulation entreprise par P. Barthélémy ?
Non seulement il n’est pas clair quelle finalité P. Barthélémy poursuit, mais ses agissements ont été perçus comme une “déception” par Jules et des admins contactés qui ont le sentiment de participer malgré eux à une tentative de décrédibilisation de l’encyclopédie :
[avant publication de l’article de P. Barthélémy]
“J’ai eu le journaliste au téléphone (une heure et quinze minutes), il a souligné à de (très) nombreuses reprises que son intention n’était pas de dégrader Wikipédia, ni de faire un article racoleur du type : « Comment j’ai piraté Wikipédia » […] Il a précisé qu’il avait déjà lu la littérature sur la fiabilité de Wikipédia, mais qu’il voulait savoir ce qu’il en était en 2017, et lorsque je lui ai fait remarquer qu’il aurait pu chercher un cas réel et préexistant de canular ou de manipulation de l’information, il a eu un temps de silence et a indiqué qu’il n’y avait pas pensé. J’ai également souligné que pour nous, Wikipédiens, c’était dans tous les cas un vandalisme – que l’auteur soit journaliste et fasse une expérience ou bien que ce soit un collégien désœuvré n’y change rien.” — Jules 11 février 2017 à 21:12 (CET)
[après publication de l’article de P. Barthélémy]
“Même si, comme Enrevseluj, j’ai trouvé le journaliste assez ouvert au téléphone, je suis déçu par l’article : même si l’on pouvait s’y attendre, cela n’apporte vraiment rien de nouveau. N’importe quel contributeur est au courant qu’il est possible de créer ce type de canular, et il aurait suffit (sic) à M. Barthélémy d’interroger un Wikipédien pour avoir des exemples réels et préexistants de manipulation (ou de fake news, pour reprendre ce terme en vogue).” — Jules 12 février 2017 à 18:56 (CET)
(source)
Il n’y a qu’à remonter les tweets outragés de nombreux professionnels de la recherche pour se rendre également compte de l’image qu’une revendication de la part de P. Barthélémy donne de la pratique de la science : il suffit d’avoir une idée dans l’air du temps et d’aller vandaliser quelques pages web pour être chercheur donc ? Dans un pays où les chercheurs sont dévalorisés, leurs moyens financiers inexistants et où la médiation et la communication scientifiques sont en voie de disparition, avons-nous vraiment besoin d’une telle démarche de la part du “Passeur de Sciences” du Monde ?
Toute l’expérience est balisée de A à Z et (paradoxalement) P. Barthélémy exclut Wikipédia du débat en refusant, de manière parfois quelque peu condescendante, le débat sur Twitter, cependant demandé par plusieurs personnes. On pourrait par exemple voir un geste d’ouverture si P. Barthélémy proposait de faire le débat sur Wikipédia, soit là où le mal a été fait. Hélas, rien de tel. Ainsi, ce qui est inclus dans l’article est entièrement à la discrétion de P. Barthélémy qui ne permet qu’un débat se déroule ailleurs que sur son blog.
On est très loin de la démarche scientifique où tout élément d’une étude peut et devra être examiné par les pairs. On est dans un univers parallèle où P. Barthélémy pose les questions, les modifie, donne des réponses ou pas, et instrumentalise ce soi-disant débat pour appeler au changement de gouvernance de l’information chez Wikipédia en français. Enfin, se soumettre à cet impérieux caprice de débat sur le blog et seulement là relèverait, comme le souligne également l’historien Alexandre Moatti, “à cautionner la démarche”.
Mais dans ce foutoir de confusions, le risque le plus sérieux n’est même pas évoqué. En effet, on peut craindre une contamination générale de la “connaissance libre” dont Wikipédia n’est qu’une partie. Citons par exemple Wikidata et toute l’architecture du web sémantique, la contribution de laquelle fait d’ailleurs l’objet de problématiques de recherche primées. Le rôle des communautés a changé depuis quelques années et elles s’imposent de plus en plus comme des outils scientifiques de référence : certaines initiatives telles Wikidata s’éloignent ainsi de la vulgarisation pour développer des pratiques et structures beaucoup plus spécialisées.
Divers aspects de l’article de P. Barthélémy, intitulé “Pourquoi et comment j’ai créé un canular sur Wikipédia”, posent problème en plus de ceux précédemment mentionnés. Le champ sémantique et les mots dont l’auteur se sert pour expliciter ses agissements créent ainsi une manière de penser et voir les acteurs de ce vandalisme sous une lumière quelque peu choquante et à coup sûr inquiétante. Si nous nous y arrêtons, c’est parce que “nommer, c’est faire exister” et parce que nous estimons qu’un journaliste, de surcroît le fondateur de la rubrique Sciences et Environnement au Monde, a une visibilité qui appelle à une grande responsabilité. Avec ce canular élaboré, P. Barthélémy a commis plusieurs impairs ; espérons que ce soient les derniers.
Barthélémy se pose ainsi dès le départ en victime d’un système qu’il respecte :
L’entrée Léophane n’existait pas sur Wikipédia et le personnage pouvait faire un candidat valable selon les critères de la célèbre encyclopédie en ligne. J’ai donc décidé de créer cette entrée en écrivant le peu que l’on connaissait sur ce savant et en inventant le reste. J’ai donc laissé libre cours à ma fantaisie, tout en lui conférant les apparences du plausible, à coups de références.
[…]
L’expérience proprement dite a commencé à la fin de décembre lorsque j’ai publié l’entrée, ce qui s’apparente à du « vandalisme sournois » selon les critères de Wikipédia.
Alors, qu’en est-il ? L’encyclopédie a des règles mais quand on les enfreint, ce n’est pas normal de se faire traiter de vandale ? C’est bien pratique comme positionnement. Cette dualité des propos et du positionnement de P. Barthélémy est caractéristique de toute sa démarche dans ce cas. Il ne se définit jamais comme journaliste, jamais comme scientifique. En se positionnant au-dehors du système qu’il souhaite “tester”, il souhaite également échapper à ses règles. Puisqu’on n’y est pas, on n’a pas de règles à respecter et donc on ne déroge à aucune règle. Logique, non ?
Dans son article en réaction, Autheuil relève bien cette dualité :
“Là où le bât blesse, à mes yeux, c’est que Pierre Barthélémy est à la fois celui qui a conçu et réalisé le test, ainsi que celui qui le relate et le porte à la connaissance du public. Les deux rôles doivent rester strictement séparés. Les journalistes ne doivent jamais construire eux mêmes les faits qui vont servir de base à leur travail d’analyse et de mise en perspective purement journalistique. Je comprend que la tentation soit grande, pour les journalistes, de se saisir de cet important problème des “fake news”. Mais ils doivent y résister, car sans le vouloir, en jouant sur les deux tableaux, ils affaiblissent la crédibilité des journalistes, ce qui renforce ceux qui cherchent à manipuler l’information.”
Barthélémy est journaliste. Qui plus est, journaliste scientifique. On en attend donc une démarche raisonnée et raisonnable et non pas une entreprise de torture des faits jusqu’à ce qu’ils avouent ce que l’on veut. En effet, en enfermant le débat et en occultant toutes les critiques faites depuis que le pot-aux-roses a été découvert, revient à travestir le vandalisme en démarche scientifique. Cela ressemble fort à la gestation d’un alternatif fact et contribue ainsi à créer ce que le journaliste du Monde prétend dénoncer.
Et si l’on transposait cette même démarche ?
“Vous êtes journaliste au Monde. Avez-vous tenté de faire des erreurs volontaires dans un sujet obscur destiné au journal papier ? sur le journal en ligne ? Avez-vous même tenté de faire un faux sur votre blog et voir s’il serait détecté ?
Je doute que ce soit bien vu. Il s’en trouvera pour dire que ça montre les failles d’un journal qui se veut sérieux, ou que vous transformez après coup le contenu erroné en fausse expérience, ou qu’à tout le moins ils ne pourront pas se fier au contenu à l’avenir faute de savoir si c’est une nouvelle expérience. Ne parlons même pas du risque d’un mauvais buzz où les gens n’entendent parler que de l’erreur mais pas de l’explication qui suit.”
L’éthique et les titres que l’on se donne veulent dire quelque chose. Alors plutôt que de répondre avec condescendance à ceux qui critiquent qu’ils ne savent rien du métier de journaliste, P. Barthélémy ferait bien de prendre exemple sur ses propres conseils à l’attention de Wikipédia : reconnaître ses erreurs, ses limites et s’améliorer.
Notre motivation de prendre position en long et en large vient du fait que nous ne considérons pas cette manipulation élaborée comme un épiphénomène. Les contradictions et nombreux problèmes de la démarche, évoqués plus haut, découlent directement de la formulation actuelle du débat. Cela a déjà été pointé mais le discours sur les fake news repose sur une vision naïve de la fiabilité (qui se réduit à l’approbation d’informations « vraies » et au rejet d’informations « fausses »).
Une telle vision binaire et le recours à du vandalisme sournois par quelqu’un qui se définit comme “Passeur de Sciences”, c’est oublier également que les termes de « fake news » ou « post-truth » mélangent des pratiques relativement distinctes qui se juxtaposent plus qu’elles ne se confondent : propagande d’États, de groupes idéologiques ou d’entreprises, canulars, erreurs factuelles, etc. La polarisation de la société ne devrait pas être renforcée par de faux semblants et des apprentis sorciers.
Si certains propos peuvent paraître trop forts ou trop acides, alors imaginez quelle est notre consternation face à ce qu’il s’est passé. Pour reprendre les lois de Newton, à chaque force s’oppose une force d’intensité au moins équivalente. Il n’y a donc aucune animosité personnelle à y lire, mais l’expression d’un désarroi profond face à un journaliste à qui nous faisions confiance d’aborder, avec intégrité et intelligence, un sujet presque-oublié en France : la médiation scientifique.
Si l’on voulait, on pourrait suggérer de très nombreux sujets d’exploration autour de Wikipédia, aucun desquels n’implique la création de fausses informations :
On vous recommande cette vidéo hilarante et très à propos, par le journaliste John Oliver de la chaîne américaine HBO à propos de Trump et ses alternatif facts, élevés au rang de politiques publiques réelles en réponse à des problèmes exagérés ou carrément imaginaires.
Et puisque notre démarche est de co-construire la connaissance en respectant la véracité des informations et le sérieux de la démarche, nous invitons Pierre Barthélémy et toute personne le souhaitant à nous aider à compléter la page recensant les diverses critiques et études scientifiques traitant de Wikipédia, ses processus et ses communautés. Comme vous l’imaginez sans doute, il y a mille et une façons dignes, respectueuses et productives de renverser le cours du flux de fausses informations qui tente de nous submerger. Soyons-en les acteurs et non pas les pourfendeurs.
L’information vient d’être relayée sur Twitter (et n’a apparemment pas encore fait l’objet de publication par ailleurs) : le conseil d’État a rejeté le décret encadrant l’exception au droit d’auteur pour la fouille de texte et de données (Text & Data Mining) à des fins scientifiques.
Ce rejet n’est pas définitif : la loi prévoit de toute manière un décret (“Un décret fixe les conditions dans lesquelles l’exploration des textes et des données est mise en œuvre”). En attendant, cela limite considérablement l’application concrète de l’exception.
Le principe de base demeure : il n’est pas illégal, au regard du code de la propriété intellectuelle, de constituer des “copies ou reproductions numériques réalisées à partir d’une source licite, en vue de l’exploration de textes et de données incluses ou associées aux écrits scientifiques pour les besoins de la recherche publique, à l’exclusion de toute finalité commerciale.”
Par exemple, j’ai extrait automatiquement plusieurs centaines articles de presse pour un projet de recherche sur le débat européen autour de la Liberté de panorama (notamment à partir de la base de données Europresse, à laquelle mon université est abonnée). J’étais alors potentiellement dans l’illégalité si je n’en faisais pas un usage strictement privé (par exemple en communiquant les copies à des collaborateurs). Aujourd’hui ce ne serait a priori plus le cas.
Par contre, en l’absence de décret d’application, les propriétaires des contenus ne sont tenus en rien de fournir ces corpus aux chercheurs ; ils ont même toute latitude de bloquer les extractions automatiques (en invoquant la nécessité de “protéger” le site des requêtes excessives). En somme, l’exception lève le risque juridique lié à l’utilisation de copies licites pour la fouille de donnée ; elle ne permet pas de récupérer ces copies (qui requièrent des arrangements contractuels au cas par cas).
Le décret d’application visait à corriger cette déficience. La dernière version en date (republiée pour l’occasion sur Sciences Communes) correspond à un texte de compromis. La préservation de la “sécurité” des infrastructures face à des requêtes multiples ne peut servir d’argument pour entraver excessivement l’extraction : les détenteurs des droits (généralement des éditeurs) peuvent “appliquer des mesures destinées à assurer la sécurité, la stabilité et l’intégrité des réseaux et bases de données, dès lors qu’elles n’excèdent pas ce qui est nécessaire pour atteindre ces objectifs”.
Les établissements de recherche sont de plus habilités à conserver “sans limitation de durée les copies techniques produites dans le cadre de l’exploration de textes et de données”. L’objectif est d’éviter de mener d’effectuer des extractions multiples (alors que des corpus peuvent avoir déjà été constitués).
Pour l’instant, l’argumentaire du Conseil d’État n’a pas encore été publié. Il sera intéressant de voir quelles dispositions du décret ont motivé le rejet (et, par contraste, quelles dispositions sont appelées à être reprises dans un futur décret).
Il semblerait également qu’une voie intermédiaire entre arrangement contractuel et cadre général soit également envisagée, sous la forme de “protocoles d’accords” intégrés dans les contrats entre les institutions de recherche et les éditeurs. Tout ceci risque de complexifier grandement la mise en œuvre de l’exception (rien ne garantit que les protocoles soient rendus publics, ni qu’ils soient systématiquement identique d’un contrat à l’autre…).
À plus long terme, une exception similaire est très sérieusement envisagée au niveau européen. Le principe d’un droit de fouille de textes et de données semble faire l’objet d’un relatif consensus : le débat porte davantage sur son extension au-delà du monde de la recherche (pour tous les usages non-commerciaux, voire pour des usages commerciaux). Le rapport Comodini, qui correspond déjà à un texte de compromis entre les différentes options retenues par le parlement européen, propose ainsi d’étendre le périmètre de l’exception à “l’innovation” (Amendement n°3) et non uniquement à la “recherche scientifique”.
Plus de 50 universités du Royaume-Uni ont fait tester leur cyberdéfense par des pirates éthiques, et les résultats sont loin d’être réjouissants.
The post Deux heures suffisent à des pirates éthiques pour hacker les défenses de plusieurs universités appeared first on WeLiveSecurity
Certains utilisateurs des services de messagerie électronique en ligne de Microsoft, comme Outlook.com, ont vu leurs informations de compte exposées lors d'un incident qui a également affecté le contenu des emails.
The post Microsoft révèle une brèche affectant les utilisateurs de messagerie Web appeared first on WeLiveSecurity
Mais bonne nouvelle, le FBI souligne les succès de sa nouvelle équipe, visant à récupérer une partie des fonds perdus dans les escroqueries du BEC.
The post Les pertes dues à la fraude BEC ont presque doublé l’an dernier appeared first on WeLiveSecurity
Les chercheurs d'ESET ont analysé de faux portefeuilles de cryptomonnaie émergeant sur Google Play, surfant sur la hausse de la valeur du bitcoin.
The post De fausses applications de cryptomonnaie apparaissent sur Google Play alors que la valeur du Bitcoin augmente appeared first on WeLiveSecurity
Cet article décrit la réparation d'une minichaine Dynabass DBT150, qui refusait obstinément de s'allumer.

La DBT150 est une minichaine sur pied, avec fonctions radio / CD / USB / AUX / Bluetooth... et celle-ci refuse de fonctionner !
On y découvre que le transformateur d'alimentation est endommagé au delà de toute possible réparation, et comment contourner le problème en remplaçant toute l'alimentation par des éléments courants.
La séparation du pied, puis le démontage du panneau arrière s'effectuent en retirant les multiples vis de la face arrière :

L'intérieur est spartiate...
Mes premiers soupçons se portent sur la carte située entre la prise secteur et le transformateur :
![]()
![]()
![]()
Le rôle de cette carte semble être de commuter, sur demande du microcontrôleur central, l'alimentation du transformateur général. Soit celui-ci est relié directement au secteur, soit il l'est à travers le condensateur rouge. S'agirait-il d'une bizarrerie visant à respecter les normes de consommation en réduisant la consommation du transformateur lorsque l'appareil est en mode de veille ?
Quoi qu'il en soit, la carte est rapidement mise hors de cause, le primaire du transformateur s'avère être ouvert. La cause semble être une diode de redressement située sur l'un des enroulements secondaires du transformateur qui est en court circuit ; le secondaire du transformateur s'est alors retrouvé en court circuit une alternance sur 2, causant un fort échauffement, et le déclenchement du thermofusible intégré à son enroulement primaire.

Feu le transformateur d'alimentation
Malheureusement, la construction du transformateur empêche toute tentative de débobinage / réparation de ce dernier, et ses caractéristiques non standard prohibent l'obtention d'une pièce de remplacement. Il va donc falloir recréer une alimentation complète. Commençons par étudier la topologie du système :
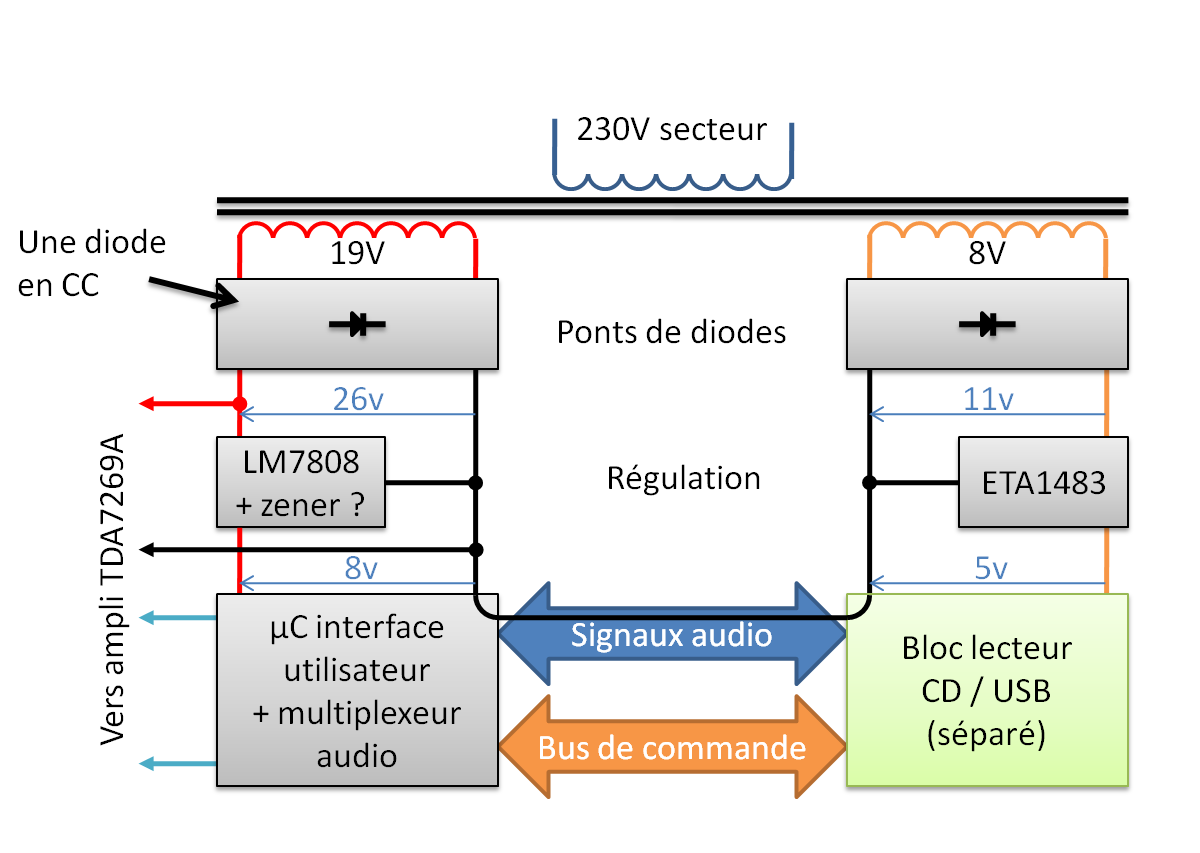
L'alimentation utilise 2 enroulements secondaires du transformateur
Étrangement, le bloc lecteur CD / USB est alimenté par un enroulement dédié du transformateur, son alimentation est totalement isolée du reste de l’électronique sur la carte principale. Cette conception m'a initialement fait craindre que les deux rails d'alimentation ne partagent pas la même masse, ce qui aurait compliqué la réalisation d'une nouvelle alimentation basée sur des éléments préexistants. Heureusement, les masses sont en réalité raccordées au sein du bloc lecteur CD / USB. Le fait de ne pas les raccorder sur la carte principale a probablement pour objectif réduire le bruit qui pourrait être causé par une boucle de masse.
Cependant, lors de la réalisation de la nouvelle alimentation, je vais devoir mettre en commun les masses au niveau de l'alimentation. Je prévois en effet une alimentation principale délivrant la tension de 26V, et l'emploi d'un convertisseur buck (DC/DC non isolé) pour générer la seconde alimentation destinée au bloc lecteur CD / USB. Ne pas raccorder la masse au niveau de l'alimentation signifierait que tout le courant retournant du bloc lecteur CD/USB circulerait à travers la masse du câble de petite section destiné aux signaux audio, ce qui au mieux dégraderait la qualité sonore de façon bien plus marquée d'une boucle de masse, ou au pire pourrait endommager ce câble.
Le schéma de la nouvelle alimentation est le suivant :
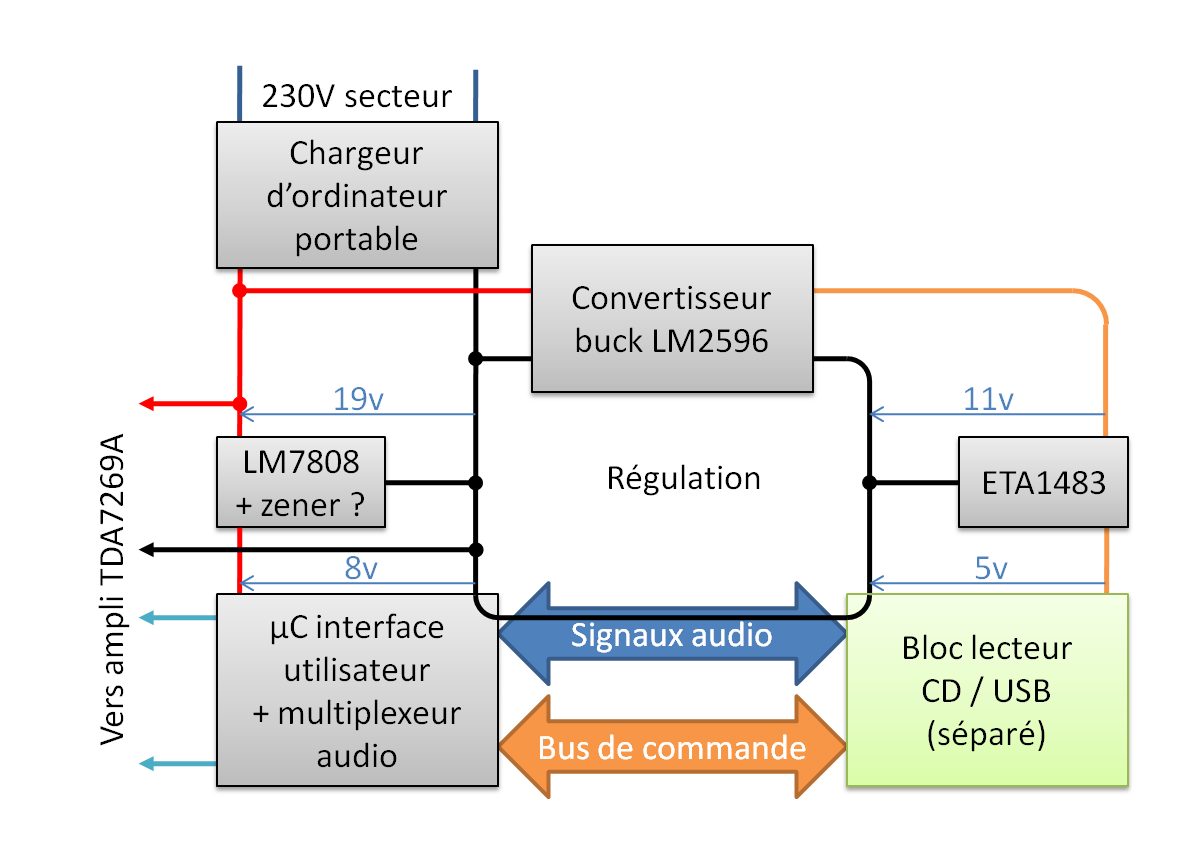
La topologie de la nouvelle alimentation
Celle-ci repose sur un chargeur de PC portable pour générer la tension principale de 19V alimentation l'amplificateur et l'essentiel de l'électronique. Bien qu'inférieure à la tension originale de 26V, celle-ci devrait suffire à délivrer un niveau sonore satisfaisant. Un module DC/DC à base de LM2596, qui prend place dans l’alcôve du transformateur, permet de générer la tension d'alimentation de 11V pour le bloc lecteur CD / USB.

Les raccordements du convertisseur DC/DC et du chargeur de PC portable sont réalisés à la place des ponts de diodes

L'emplacement original de la connectique secteur contient maintenant le raccordement du chargeur de PC portable
Vient le moment fatidique, la mise sous tension !
Tout fonctionne parfaitement, aucune saturation détectable à l'oreille (c'était ma principale inquiétude quant à l'emploi d'une tension plus faible que celle d'origine)

La chaine en fonctionnement avec sa nouvelle alimentation
Un effet intéressant lié à l'utilisation d'une alimentation à découpage à place de l'ancienne alimentation : lorsque l'on débranche le secteur, l'alimentation se maintient pendant plusieurs seconde (le chargeur de PC portable est prévu pour délivrer jusqu'à 4A, ici on consomme rarement plus de 0.5A). Donc pas d'interruption de la musique en cas de micro-coupure du réseau EDF !
En espérant que si toi lecteur tu es arrivé jusqu'ici, c'est que cet article t'a permis de réparer ta minichaine ![]()
Commercialisée par ASUS début 2014, la GTX780 ROG Poseidon est une carte graphique haut de gamme, dotée de 3 Go de VRAM, et d'un système de refroidissement hybride : celui-ci est en effet composé d'un large dissipateur, épaulé par 3 caloducs, et refroidit par 2 ventilateurs, mais intègre également un (court) circuit eau, permettant un refroidissement par watercooling.
Ce système de refroidissement est également muni d'un logo "Republic Of Gamer" rouge clignotant, jouant sans aucun doute un rôle extrêmement important dans le fonctionnement de la carte, tel que changer un PC en discothèque, ou pire encore ...

l'ASUS GTX780 ROG POSEIDON (ventilateurs débranché)
Et c'est justement ce système de refroidissement qui m'a donnée du fil à retordre, puisqu'un beau jour, les ventilateurs ont tout bonnement cessé de fonctionner. Si cela ne pose aucun problème visible en utilisation bureautique de la carte (la fréquence ainsi que la tension d'alimentation du GPU étant fortement réduites dans ce type d'utilisation, la faible dissipation thermique qui en résulte permet de maintenir le GPU dans une plage de température acceptable, même sans aucun ventilateur en fonction), lors d'une utilisation pour du rendu 3D (principalement en jeu), c'est une toute autre histoire, la température du GPU augmentant rapidement de manière alarmante, jusqu'à son arrêt pur et simple, provoquant une perte de l'affichage jusqu'au redémarrage de la machine.
J'ai donc entrepris d'en réparer le système de refroidissement ...
Les 2 ventilateurs ne démarrant pas, mais tournant cependant librement sur leur axe, ma première hypothèse fut que le contrôleur des ventilateurs, intégré à la carte, avait cessé de fonctionner. Pour vérifier cela, rien de plus simple, il suffit de démonter les ventilateurs, et de les tester indépendamment. Séparer les les ventilateurs du dissipateur n'est pas une mince affaire, et implique de se battre contre plusieurs clips plastiques, visibles après coup sur la photo ci dessous :

Les ventilateurs enfin séparés du dissipateur
Les ventilateurs sont alors testés séparément, à l'aide d'une alimentation de laboratoire, réglée pour fournir 12V (1A max) via le connecteur 5 points qui les relie normalement à la carte graphique, et ...

Rien ne se passe ....
Comment ça, rien ?? Enfin, pas exactement rien, l'alimentation de labo indique 0V, 1A, c'est un court circuit franc ! Fichtre, un des ventilateurs est sans doute décédé ...
Avant d'aller plus loin, observons le câblage des dits ventilateurs : comme écrit précédemment, ceux-ci sont raccordés à la carte graphique par le biais d'un connecteur 5 points, véhiculant les signaux suivants : Masse, +12V, commande PWM pour la vitesse, ainsi que 2 signaux de retour indiquant la vitesse effective de chaque ventilateur. De ce connecteur partent 2 séries de fils : l'une va sur un ventilateur, tandis que l'autre dessert un second connecteur, d'où partent également 2 séries de fils : l'une desservant le second ventilateur, et l'autre alimentant le logo ROG clignotant.
Et si ... ?
Essayons à nouveau avec le fameux logo ROG débranché :

Le logo ROG débranché, les ventilateurs reviennent à la vie
Cette fois, les ventilateurs s'animent ! Plus de court circuit, qui provenait donc du logo clignotant.
En le démontant, on découvre un PCB relativement simple, comportant quelques leds, un jeu d'AOP LM324, ainsi que quelques composants génériques, rien de bien folichon :
![]()
![]()
Je n'ai pas pris le temps d'autopsier ce module, peu importe, son fonctionnement était agaçant de toute façon...
Ses ventilateurs réinstallés, la carte prend place dans mon PC, et c'est l'instant fatidique : démarrage !

la GTX780 en phase de test
Et les ventilateurs ne tournent toujours pas...
Ce qui, après réflexion, semble assez logique : un court circuit aussi franc que celui qui a eu lieu ici sur l'alimentation des ventilateurs à forcément endommagé le circuit d'alimentation des ventilateurs. Sans doute trouvera-t-on une piste brulée, ou un shunt grillé sur le PCB de la carte.
Cette recherche nécessite de séparer le système refroidissement du PCB de la carte, opération que j'avais jusqu'alors soigneusement évitée, étant précédemment en pénurie de pâte thermique, indispensable lors du ré-assemblage pour remplacer la pâte thermique d'origine, qui ne survit pas au démontage.

Le système de refroidissement séparé du PCB
Une fois le PCB entièrement accessible, on s’intéresse aux pistes menant au connecteur 5 pins qui alimente les ventilateurs. Et il ne faut pas longtemps pour identifier un coupable potentiel :

Juste à coté du connecteur, ce shunt semble avoir rendu l’âme
A proximité du connecteur, raccordé à la broche délivrant le +12V au système de refroidissement, une résistance marquée 0 (ayant donc un rôle de shunt ou de fusible) porte des traces de dommages. Elle est immédiatement remplacée :

La résistance remplacée. note pour la prochaine fois : acheter du nettoyant de flux
Une fois la résistance remplacée, la carte est réassemblée, le GPU recouvert de pâte thermique Artic Silver MX2, et reprend place dans mon PC.
Démarrage, et les ventilateurs s'animent enfin !
![]()
![]()
Windows se lance sans problème, mais surtout, la carte reste en fonctionnement lors d'applications 3D, avec des températures honorables de l'ordre de 70 °C !
Bref, une franche réussite. Il est cependant dommage que cette panne soit causé par un élément aussi insignifiant (et inutile) que le logo clignotant ! Il aurait été sage de la part d'ASUS de lui fournir son propre rail 12V, ou encore plus simplement, de le doter de son propre fusible, afin que sa défaillance n'interfère pas avec le fonctionnement du système de refroidissement !
Ayant été confronté à la configuration de cette machine à pince, et devant le peu de documentation disponible sur le web, j’ai décidé de rédiger ce bref article regroupant mon expérience avec cette machine
La configuration s’effectue en enclenchant l’interrupteur situé derrière le monnayeur. Attention, contrairement aux apparences, il s’agit d’un interrupteur 2 à positions stables : 1 appui passe en mode configuration, et un second appui est nécessaire pour en sortir.
Les différents paramètres sont reconnaissables par leur numéro sur l’afficheur 7 segment. On passe au paramètre suivant en poussant le joystick vers la gauche, et on change la valeur en poussant le joystick vers la droite. Certains paramètres ne sont pas modifiables, comme les compteurs de nombre de parties.
L’ensemble des paramètres disponibles sont regroupés dans le tableau suivant. Malheureusement, le rôle de certains m’échappent encore (la fonction de ces paramètres est marquée d’un point d’interrogation dans le tableau), si vous en savez plus, n’hésitez pas à me contacter, je mettrai à jour cet article.
| Paramètre | Valeur orig | Valeurs possibles | Incrément | Fonction |
| 1 | 0 | [0:1] | 1 | ? |
| 2 | 10 | [0:10] | 1 | Nombre arrêt descente pince possibles |
| 3 | 0 | [0:1] | 1 | Descente pince dans conduit |
| 4 | 50 | 0 + [50:99] | 1 | Rentabilité ? |
| 5 | 0 | [0:1] | 1 | Désactiver son descente pince |
| 6 | 0 | [0:1] | 1 | Désactiver autre son ( son gagnant ) ? |
| 7 | 0 4155 | Compteur nombre de crédits | ||
| 8 | 0 0622 | Compteur parties gagnées | ||
| 9 | 0 0002 | Compteur triche monayeur ? | ||
| 10 | ? | |||
| 11 | 10 | [10:30] | 5 | Durée partie |
| 12 | 2 | [0:10] | 1 | Nombre de pièces (1€) pour jouer |
| 13 | 1 | [0:10] | 1 | Nombre de parties |
| 14 | 0 | [0:1] | 1 | Autoriser mouvement pince au sol |
| 15 | 1 | [0:1] | 1 | ? |
| 16 | 0 | [0:1] | 1 | ? |
Pour valider la configuration souhaitée, il suffit de repasser en mode exploitation, en appuyant sur le bouton situé derrière le moniteur.
Dans l’environnement où cette machine est utilisée (coupures de courant fréquentes), il est vite apparu que cette machine avait un gros défaut de fiabilité. Des dysfonctionnement réguliers, allant du changement de valeur aléatoire de certains paramètres de la configuration, au refus pur et simple d’accepter des pièces, furent observés. Tous ayant pour point commun des valeurs aberrantes de certains paramètres ( parfois totalement en dehors de la gamme de valeurs possibles ). Il est vite devenu évident que l’EEPROM stockant les paramètres devenant corrompue, probablement à la suite d’une coupure de courant intervenue au mauvais moment (lors de l’écriture de l’EEPROM).
La documentation de ce CI indique qu’une broche (nommée WP), permet, en la raccordant au VCC, d’empêcher l’écriture de l’EEPROM, ce qui résoudrait sans doute mon problème de fiabilité !
Malheureusement, cette broche est reliée à la masse via une piste située juste en dessous de l’EEPROM. Il est donc d’abord nécessaire de dessouder cette dernière, pour pouvoir couper cette piste :
Ensuite, il ne reste plus qu’à réinstaller l’EEPROM, une résistance de 1kohms tirant cette broche à la masse, et un petit cavalier permettant de la raccorder directement au VCC, engageant ainsi la protection en écriture :
Attention tout de même : il est nécessaire de retirer le cavalier avant de modifier la configuration de la machine, sans quoi les modifications ne seront pas appliquées. De plus, en cas de coupure de courant pendant une partie, les crédits en cours ne sont plus sauvegardés ! Dans mon cas, la machine étant exploitée comme objet de décoration, il s’agit plus d’un avantage que d’un inconvénient.
Cette machine étant utilisée en décoration et comme objet de loisir, le monnayeur a été retiré, et remplacé par un détecteur optique ( réalisé à partir d’un détecteur optique à fourche), créditant toute pièce et la rendant immédiatement au joueur. Quelques photos de cette modification :
Si cet article vous a été d’une aide précieuse, ou si vous pensez qu’une information est manquante, n’hésitez pas à m’en faire part dans les commentaires !
Attention : valable uniquement pour les versions de ESP-IDF non basées sur CMAKE ( versions < 4.0 )
Travaillant actuellement sur un projet nécessitant une interface audio en bluetooth, je me suis tourné vers la solution la plus en vogue, l’ESP32.
Embarquant Wifi, Bluetooth (dont BLE), un CPU dual core avec 4 Mo de Flash, mais également très abordable, il dispose également d’un SDK entièrement open-source, très bien documenté !
La procédure d’installation de ce SDK nécessitant de modifier certaines variables d’environnement ( en particulier la variable PATH ), et n’aimant pas modifier des éléments aussi critiques du système ( il est possible en modifier de PATH de remplacer certaines commandes du système à l’insu de l’utilisateur ! ), j’ai donc, avant toute expérimentation avec l’ESP32, pris le temps d’écrire un petit script bash.
Ce script permet de démarrer un nouvel interpréteur BASH contenant les variables d’environnements permettant le bon fonctionnement du SDK ESP32, sans affecter les variables d’environnement utilisées par tous les autres terminaux du système. De plus, il possède un prompt de commande personnalisé, afin de distinguer rapidement le terminal utilisé pour le SDK.
Son contenu, succin, est le suivant :
!/bin/bash
bash --rcfile <(cat ~/.bashrc; echo 'PS1="\e[33;1mesp32 \$\e[0m "' ; echo 'export PATH="$HOME/esp32/xtensa-esp32-elf/bin:$PATH"' ; echo 'export IDF_PATH="$HOME/esp32/esp-idf"')
Attention : il est supposé que l’ensemble des fichiers nécessaires au SDK se trouvent dans le dossier ~/esp32. Si ce n’est pas le cas, modifier les chemins en conséquence
Il suffit d’exécuter le script pour obtenir un interpréteur BASH adéquat, et de quitter l’interpréteur (commande »exit », ou CTRL+D) pour revenir à un terminal normal.
J’ai testé son fonctionnement quelques heures, et en suis tout à fait satisfait. N’hésitez pas à me communiquer tout bug, ou amélioration possible !
We spent the weekend knee-deep in marinade. (Top tip: if you’re brining something big, like a particularly plump chicken, buy a cheap kitchen bin. The depth makes it much easier than juggling near-overflowing buckets. And when you’re finished, you have a spare bin.)
![]()
If you’re a serious barbecue jockey, you’ll want to know about Bryan Mayland’s HeaterMeter, a rather nifty open-source controller for your barbecue, built around a Raspberry Pi. Controlling the heat of your setup is key in low, slow cooking and smoking; you can get glorious results very inexpensively (an off-the-shelf equivalent will set you back a few hundred pounds) and have the satisfaction of knowing you built your equipment yourself. Bryan says:
Temperature data read from a standard thermistor (ThermoWorks, Maverick) or thermocouple probe is used to adjust the speed of a blower fan motor mounted to the BBQ grill to maintain a specific set temperature point (setpoint). A servo-operated damper may optionally be employed. Additional thermistor probes are used to monitor food and/or ambient temperatures, and these are displayed on a 16×2 LCD attached to the unit. Buttons or serial commands can be used to adjust configuration of the device, including adjustment of the setpoint or manually regulating fan speeds.
The Raspberry Pi adds a web interface, with graphing, archives, and SMS/email support for alarm notification, which means you can go and splash around in the kids’ paddling pool with a beer rather than spending the day standing over the grill with a temperature probe.
![]()
You can buy a HeaterMeter online, in kit form or pre-assembled. There’s an incredibly comprehensive wiki available to get you going with the HeaterMeter, and a very straightforward Instructable if you’re just looking for a quick setup. If you’re the type who prefers to learn by watching, Bryan also has a few videos on YouTube where he puts the kit together. To start with, see how to assemble the LCD/button board here and the base board here.
We’re hungry.
The post HeaterMeter, the open-source barbecue controller appeared first on Raspberry Pi.
D’après Émilien Ruiz, les humanités numériques se trouvent “à la croisée des chemins”. Cette communauté transdisciplinaire a émergé depuis plus de 10 ans, soit suffisamment de temps pour que les pratiques du futur deviennent celles du présent. Ou pas…
Car si les humanités numériques se sont ancrées institutionnellement, les promesses de renouveau scientifique et pédagogique restent encore à l’état de perspectives plus ou moins lointaines : « à ce stade, il me semble pourtant qu’il est possible de parler d’un demi-échec ». Les enseignements du numérique demeurent périphériques. Il y a eu une inflexion réelle dans les pratiques de recherche, les bases de données et les corpus en ligne devenant de plus en plus des outils “normaux” et attendus, mais avec finalement peu d’incidence sur les méthodes et sur les manières d’aborder et de construire l’objet de recherche. Au plus une révolution de l’indexation scientifique, mais certainement pas une révolution scientifique.
Émilien remarque avec justesse que ce bilan en demi-teinte a eu une incidence sur la définition-même des humanités numériques. La dimension quantitative et “computationnelle” a été progressivement reléguée au second plan, au profit d’une approche communicationnelle mettant l’accent sur l’éditorialisation et la diffusion des résultats. Les humanités numériques apparaissent davantage comme une étape supplémentaire dans le cycle de la recherche, sans altérer en profondeur l’existant.
À ce stade, l’on peut légitimement se demander si l’ambition principale des humanités numériques ne devraient pas être de “disparaître”. Réagissant au constat d’Émilien, Paul Bertrand appelle à la « fin nécessaire et heureuse des humanités numériques », appelées à se dissoudre dans les disciplines existantes. Si l’on se limite au versant communicationnel et éditorial des humanités numériques, cette réaction est amplement justifiée. Créer un site ou un carnet de recherche, alimenter une base de données, formater et visualiser un corpus devraient effectivement faire partie de l’outillage ordinaire des disciplines.
Mes recherches en cours m’amènent de plus en plus à faire le constat inverse : toutes les humanités numériques ne sont pas solubles. Ou plutôt, dans ce mouvement volontairement vague et informe, quelque chose a émergé qui change notre rapport aux objets, au savoir. Quelque chose qui ne représente qu’une partie des humanités numériques mais qui resterait même si toutes les pratiques estampillées DH venaient à se normaliser et à rentrer dans le giron de leurs disciplines d’origine. Quelque chose qui réactualise la dimension quantitative marginalisée mais en faisant autre chose que “l’histoire quantitative”.
Cette approche n’a pas vraiment de nom, ou plutôt, les labels existants ne sont pas satisfaisants : il est tantôt question de « computational literature studies » (sauf que cela ne se limite absolument à la littérature), de « lecture distante » (sauf qu’une part essentiel de la recherche actuelle porte sur des objets qui ne sont pas lus mais vus) ou de cultural analytics (expression qui se traduit terriblement mal en français et, sans doute, dans d’autres langues européennes). On pourrait aussi tenter une définition purement SHS, sans jamais faire allusion à l’informatique et parler, par exemple, de poétique historique des formes culturelles.
À défaut de nom, l’approche se caractérise par une intégration croissante de pratiques, de concepts, d’outils et de méthodes, plus ou moins marquées selon les contextes. Aux États-Unis il existe une revue dédiée qui fédère une petite communauté très active, le Journal of Cultural Analytics. En France les initiatives demeurent encore assez isolées.
Le point de départ fondamental, c’est la numérisation de masse. Les bibliothèques numériques contiennent aujourd’hui une part substantielle des productions imprimées voire écrites. Je dispose ainsi d’environ un quart des éditions de romans de 1800 à 1900 (soit la totalité de ceux qui ont été numérisés par Gallica). Dans le cadre du projet Numapresse, nous commençons à réunir une bonne partie de la presse quotidienne nationale.
Si nous sommes encore loin de l’idéal d’une numérisation totale (qui ne relève néanmoins plus de l’utopie à moyen terme), il y a aujourd’hui suffisamment de ressources accessibles pour mettre en évidence des phénomènes culturels réguliers qui débordent totalement des narrations historiques courantes. Il existe des récurrences dans les manières d’écrire, dans les arrangements éditoriaux des textes, dans les figures visuelles (d’où d’ailleurs la notion de “stéréotype”).
Par exemple, à partir du début du XIXe siècle, la presse française introduit un objet éditorial, le feuilleton, sorte de supplément interne au journal, où va notamment se nicher le roman-feuilleton. Ce qui est moins connu et qui a été rendu pleinement visible par la numérisation de collections très variées, c’est que la forme feuilleton va s’exporter dans une bonne partie de l’Europe continentale et sans doute au-delà mais pas dans les pays anglo-saxon.
Ces régularités constituent autant un standard documentaire qu’un fait social : à un certain moment, il va de soi que l’on va composer un texte d’une certaine façon, l’illustrer d’une certaine manière, à partir du moment où l’on souhaite aborder tel thématique et s’adresser à tel public.
À partir du moment où il est question de “régularités” et de “récurrences” il devient envisageable d’utiliser des méthodes quantitatives. On peut compter les feuilletons tout comme on peut compter les titres de romans qui mentionnent un genre précis, par exemple “roman de mœurs”, dans leur titre. Et à partir de ces décomptes l’on peut commencer à observer des tendances temporelles et/ou des répartitions géographiques.
Compter à la main de tels objets est une activité plutôt rébarbative même si elle a été pratiquée dans certains domaines (comme les media studies). La numérisation rend possible de déléguer cette activité à des outils automatisés. Dans certains cas, les calculs sont triviaux : compter des occurrences, agréger des publications, dessiner un graphe de tendance… Rapidement, il devient nécessaire d’utiliser des outils plus complexes.
Certaines régularités peuvent en effet apparaître évidentes à un œil humain, a fortiori un peu familier du contexte culturel d’origine du document. Je sais reconnaître le feuilleton d’un journal presque instantanément. Créer une définition du feuilleton ou de la note de bas-de-page qui soit compréhensible pour un outil automatisé est une tâche beaucoup plus ardue — on parle aussi d’opérationnalisation. Cela suppose de réfléchir sur un regard qui semble de prime abord spontané : « qu’est-ce que je vois précisément lorsque je distingue un feuilleton ? ».
Il est possible de fournir des règles précises pour repérer les objets (c’est ce que l’on appelle une approche « rule-based ») ou au contraire de laisser l’outil informatique extrapoler les règles à partir de corpus annotés. La seconde approche a été par exemple retenue pour une tentative d’identification automatisée des notes de bas de page dans des corpus anglo-saxon du XVIIIe — une pratique éditoriale notablement différentes des notes actuelles, caractérisées par l’emploi de signes spécifiques en lieu et place des numéros.
J’ai eu recours à la première approche par règle pour extraire automatiquement les romans-feuilleton du Journal des débats. Le texte journalistique était alors suffisamment standardisé pour se contenter d’une définition relativement triviale (un texte, en bas du journal déparé par une marge importante — la grande barre sombre ne survit pas au processus de numérisation/ocr).
J’ai d’ailleurs pu constater que cette approche cesse de fonctionner correctement à partir du début du XXe siècle, signe parmi d’autres que l’économie générale des formes journalistiques était en train de changer profondément. Mes travaux actuels visent à aller plus loin que l’identification d’une seule forme journalistique pour reconstituer l’architecture éditoriale générale de la presse quotidienne au XIXe siècle (et, idéalement, au XXe siècle), en anticipant notamment les articulations régulières en forme et sémantique du texte — par exemple, les signatures sont toujours justifiées à droite et les titres sont toujours centrés.
J’ai beaucoup insisté sur la “modélisation éditoriale” car elle constitue un exemple très parlant visuellement, mais les mêmes principes peuvent être appliquées à d’autres formes culturelles. C’est évidemment le cas depuis déjà quelques temps pour les textes, notamment à la suite des recherches pionnières de Ted Underwood sur l’usage critique et « détourné » des classifications supervisées pour interroger la construction historique de la généricité. Il est de nouveau question de partir d’une définition plus ou moins naïve de certaines catégories textuelles pour repérer les phases de formation d’un genre et l’évolution de sa composition lexicale.
L’interrogation critique des modèles de classification permet de sortir d’une approche d’indexation pure pour soulever des questionnements scientifiques : où ces formes se sont-elles développées ? comment se généralisent-elles et à quels moment ? dans quel contexte éditorial ?
Cette “lecture distante” peut également porter sur des régularités plus élémentaires : figures de styles, tournures, articulation récurrents de concepts. Certaines recherches plus expérimentales utilisent ainsi de nouvelles techniques de linguistique computationelle, les Word Embeddings, pour cartographier des usages poétiques sous-jacents de vastes corpus.
Le potentiel de la classification est peut-être encore plus important pour les formes visuelles. Contrairement aux textes les images ne sont pas préalablement indexées dans les bibliothèques patrimoniales. Sauf à disposer d’un paratexte explicite elles restent généralement introuvables, et même dans ces cas-là, il est difficile d’identifier précisément des régularités visuelles, qui ne relèvent pas forcément du sujet figuré mais aussi du mode de figuration. Les nouvelles techniques de classification automatisée rendent tout simplement possible une poétique historique de l’image à grande échelle.
Les méthodes informatisées s’intègrent d’autant plus naturellement dans ce projet que les régularités se déploient fréquemment sur une échelle temporelle ample. L’histoire éditoriale de la forme feuilleton commence vers la toute-fin du XVIIIe siècle et s’achève vers les années 1970 et 1980 en France (les occurrences les plus tardives que j’ai pu identifier se trouvent dans des périodiques régionaux des années 1970). Aux États-Unis la plupart des chercheurs en cultural analytics ont empiriquement acquis une expertise chronologique ample — souvent de 1800 voire 1700 à aujourd’hui.
En bref, depuis quelques années, une bonne partie de mon travail de recherche consiste à “opérationnaliser” des objets éditoriaux et des concepts . Et je serais bien en peine de dire précisément à quelle discipline correspond cette activité. Ce n’est pas de l’histoire, de la littérature, de la sociologie, de l’histoire de l’art, de la linguistique ou de l’informatique mais quelque chose qui croise ces disciplines et un peu plus encore.
L’enjeu fondamental des nouvelles méthodes de lecture distante ou de cultural analytics va au-delà de l’intégration de l’outil numérique dans des pratiques de recherches préexistantes qui ne sont pas appelées à changer en profondeur. Il s’agit bel et bien de proposer une redéfinition des frontières scientifiques, principalement au sein des sciences humaines et sociales, via, notamment, l’articulation paradoxale et constante entre observation minutieuse des réalités poétiques, éditoriales et documentaires et, d’autre part, l’ambition d’historicisation à grande échelle de formes culturelles.
Les transformations les plus marquantes, de mon point-de-vue, concerne les pratiques quotidiennes de la recherche. La programmation implique inévitable une textualisation et une explicitation des regards de recherche et des méthodes de travail. Il ne suffit pas de repérer instantanément que le feuilleton est en bas de page ou que les signatures sont systématiquement alignées à droite, il faut l’exprimer clairement en pourcentage de page ou en pourcentage de colonnes.
L’ampleur des corpus analysé et le recours à la programmation implique également de repenser l’organisation de la journée. Au-delà d’une certaine taille l’automatisation n’est pas instantanée : elle peut prendre plusieurs heures voire plusieurs jours. Je constate ainsi que je suis de plus en plus amené à anticiper les tâches à accomplir pour qu’elles tournent en mon absence (notamment pendant la nuit).
Disons-le clairement ces pratiques de recherche sont encore marginales, même au sein des humanités numériques. Je suis de plus en plus convaincus qu’elles sont appelées à se généraliser. Certes, les outils sont encore mal adaptés, les compétences manquent à l’appel, les corpus plus ou moins disponibles et dans un état plus ou moins hétérogènes, mais il y a un facteur plus important : c’est très tentant. Lorsqu’on s’intéresse aux collections patrimoniales et aux archives au sens large l’on est inévitablement confronté à tout ce savoir latent que je viens de décrire. L’on se familiarise avec les règles éditoriales, les marqueurs lexicaux de la généricité (que nous avons inévitablement assimilés lorsque nous procédons par lecture flottante) ou les stéréotypes visuels que l’on se résigne à cantonner dans un vague arrière-plan culturel sans pouvoir imaginer de décrire systématiquement une telle masse documentaire en dehors de quelques échantillons ponctuels.
Des chercheurs d'ESET découvrent des manœuvres frauduleuses s'appuyant sur la popularité de l'outil de modification de visage FaceApp, utilisant une fausse version « Pro » de l'application comme leurre.
The post Avec l’attrait suscité par FaceApp, de nouvelles escroqueries apparaissent appeared first on WeLiveSecurity
La campagne frauduleuse est hébergée par un domaine regroupant plusieurs autres arnaques prétendant provenir d'autres marques connues.
The post Une arnaque se fait passer pour WhatsApp et prétend offrir un accès Internet gratuit appeared first on WeLiveSecurity
We collected some of the most common Raspberry Pi 4 questions asked by you, our community, and sat down with Eben Upton, James Adams, and Gordon Hollingworth to get some answers.
Raspberry Pi 4 Q&A
We grilled our engineers with your Raspberry Pi 4 questions Subscribe to our YouTube channel: http://rpf.io/ytsub Help us reach a wider audience by translating our video content: http://rpf.io/yttranslate Buy a Raspberry Pi from one of our Approved Resellers: http://rpf.io/ytproducts Find out more about the #RaspberryPi Foundation: Raspberry Pi http://rpf.io/ytrpi Code Club UK http://rpf.io/ytccuk Code Club International http://rpf.io/ytcci CoderDojo http://rpf.io/ytcd Check out our free online training courses: http://rpf.io/ytfl Find your local Raspberry Jam event: http://rpf.io/ytjam Work through our free online projects: http://rpf.io/ytprojects Do you have a question about your Raspberry Pi?
Do you have more questions about our new board or accessories? Leave them in the comments of our YouTube video, or in the comments below, and we’ll collect some of the most commonly asked questions together for another Q&A session further down the line.
The post We asked our engineers your Raspberry Pi 4 questions… appeared first on Raspberry Pi.
Un nouveau rapport souligne que jusqu'à 30 pour cent des victimes de fraude amoureuse en 2018 auraient été utilisées comme passeurs d’argent.
The post Le FBI met en garde contre les escroqueries amoureuses au blanchiment d’argent appeared first on WeLiveSecurity
This week the post office delivered a package that made me very satisfied. It was a box with three paper versions of my "Web Development with Django Cookbook - Second Edition". The book was published at the end of January after months of hard, but fulfilling work in the late evenings and at weekends.
The first Django Cookbook was dealing with Django 1.6. Unfortunately, the support for that version is over. So it made sense to write an update for a newer Django version. The second edition was adapted for Django 1.8 which has a long-term support until April 2018 or later. This edition introduces new features added to Django 1.7 and Django 1.8, such as database migrations, QuerySet expressions, or System Check Framework. Most concepts in this new book should also be working with Django 1.9.
My top 5 favourite new recipes are these:
The book is worth reading for any Django developer, but will be best understood by those who already know the basics of web development with Django. You can learn more about the book and buy it at the Packt website or Amazon.
I thank the Packt Publishing very much for long cooperation in the development of this book. I am especially thankful to acquisition editor Nadeem N. Bagban, content development editors Arwa Manasawala and Sumeet Sawant, and technical editor Bharat Patil. Also I am grateful for insightful feedback from the reviewer Jake Kronika.
What 5 recipes do you find the most useful?
Le vendredi fou et le cyberlundi sont là et les arnaqueurs se préparent à vous inonder d'offres bidon. Quelques arnaques desquelles vous méfier!
L'article Cinq escroqueries desquelles se méfier pour cette saison de magasinage a d'abord été publié sur WeLiveSecurity
Today is Giving Tuesday. Giving Tuesday takes place on the day following the well-known shopping days of Black Friday and Cyber Monday, as a celebration of the generosity of the human spirit. It’s your chance to give something back, or to pay it forward, whichever feels right to you.
There is now plenty of evidence for what we all know intuitively to be true: giving makes you happy.
Whether it’s giving gifts for Christmas, volunteering your time for a cause that you care about, or donating some of your hard-earned cash to support a nonprofit organisation, there’s a proven neural link between generosity and happiness (if you want to check the science, this recent study is a good place to start).
Help young people get creative with coding and hardware!
This link certainly exists for the tens of thousands of people who give their time to support young people at Code Clubs and CodeDojos; whenever I ask volunteers why they give their time, they consistently talk about the feeling of joy they experience when they see a young person having a breakthrough and learning something new.
We’re coming to the end of another remarkable year at the Raspberry Pi Foundation, and I wanted to use this Giving Tuesday to say thank you to all of our supporters.
You can become part of a movement that empowers young people to express themselves through creative tech projects.
Taken together, that’s millions more young people learning how to create with digital technologies, many of whom wouldn’t otherwise have had the opportunity to discover the power of digital making.
We couldn’t achieve any of this without the incredible generosity of our supporters, who give their time, expertise, and money to bring our work to life.
If you’d like to experience some of the unadulterated joy that comes with supporting the mission of the Raspberry Pi Foundation, it couldn’t be easier:
If you want to get involved in supporting the next generation of digital makers, you can support us with a one-off or regular donation: www.raspberrypi.org/donate
Thank you, and happy Giving Tuesday!
The post Support the Raspberry Pi Foundation this #GivingTuesday appeared first on Raspberry Pi.
L'app clavier app ai.type pour Android, avec 40 millions de téléchargements, inscrivait des utilisateurs à des services premium sans leur consenteme
L'article Une application clavier Android prise en flagrant délit d’essayer de faire des achats sournoisement a d'abord été publié sur WeLiveSecurity
Des courriers électroniques infectés par des logiciels malveillants aux fausses organisations caritatives, méfiez-vous des arnaques se servant du contexte de cette crise de la santé publique.
L'article Méfiez‑vous des arnaques exploitant les craintes liées aux coronavirus a d'abord été publié sur WeLiveSecurity
Des escroqueries qui exigent un paiement en bitcoin, sous peine de vous infecter avec le coronavirus, remportent une place au panthéon des arnaques les moins crédibles.
L'article Escroqueries, mensonges et coronavirus a d'abord été publié sur WeLiveSecurity
Have all of y’all been hoarding toilet roll over recent weeks in an inexplicable response to the global pandemic, or is that just a quirk here in the UK? Well, the most inventive use of the essential household item we’ve ever seen is this musical project by Max Björverud.
Ahh, the dulcet tones of wall-mounted toilet roll holders, hey? This looks like one of those magical ‘how do they do that?’ projects but, rest assured, it’s all explicable.
Max explains that Singing Toilet is made possible with a Raspberry Pi running Pure Data. The invention also comprises a HiFiBerry Amp, an Arduino Mega, eight hall effect sensors, and eight magnets. The toilet roll holders are controlled with the hall effect sensors, and the magnets connect to the Arduino Mega.
In this video, you can see the hall effect sensor and the 3D-printed attachment that holds the magnet:
Max measures the speed of each toilet roll with a hall effect sensor and magnet. The audio is played and sampled with a Pure Data patch. In the comments on his original Reddit post, he says this was all pretty straight-forward but that it took a while to print a holder for the magnets, because you need to be able to change the toilet rolls when the precious bathroom tissue runs out!
Max began prototyping his invention last summer and installed it at creative agency Snask in his hometown of Stockholm in December.
The post These loo rolls formed a choir appeared first on Raspberry Pi.
Le message d’extorsion comprend le mot de passe de la victime potentielle comme preuve d'un piratage, mais il y a plus à savoir sur cette stratégie.
L'article Les cybercriminels continuent d’utiliser des mots de passe volés pour des campagnes de sextorsion a d'abord été publié sur WeLiveSecurity
Les arnaqueurs reprennent de vieilles techniques, créent des sites web de vol de cartes de crédit et réorientent les canaux d'information pour exploiter au maximum la crise COVID-19.
L'article Il n’est pas temps de baisser la garde, les arnaques aux coronavirus restent une menace a d'abord été publié sur WeLiveSecurity
Vous êtes peut-être à la recherche d’un cadeau pour votre mère. Voici quelques types de fraude courants à surveiller en cette Fête des mères.
The post Des escroqueries à surveiller, pour la fête des mères et à l’année appeared first on WeLiveSecurity
One of our Approved Resellers in the Netherlands, Daniël from Raspberry Store, shared this Raspberry Pi–powered prayer reminder with us. It’s a useful application one of his customers made using a Raspberry Pi purchased from Daniël’s store.
As a Raspberry Pi Official Reseller, I love to see how customers use Raspberry Pi to create innovative products. Spying on bird nests, streaming audio to several locations, using them as a menu in a restaurant, or in a digital signage-solution… just awesome. But a few weeks ago, a customer showed me a new usage of Raspberry Pi: a prayer clock for mosques.
Made by Mawaqit, this is a narrowcasting solution with a Raspberry Pi at its heart and can be used on any browser or smartphone.
This project is simple in hardware terms. You just need Raspberry Pi 3 or Raspberry Pi 4, a TV screen, and a HDMI cable.
If you do not have an internet connection, you’ll also need an RTC clock
With the HDMI cable, Raspberry Pi can broadcast the clock — plus other useful info like the weather, or a reminder to silence your phone — on a wall in the mosque. Awesome! So simple, and yet I have not seen a solution like this before, despite Mawaqit’s application now being used in 51 countries and over 4609 mosques. And, last I checked, it has more than 185,000 active users!
You’ll need to install the pre-configured system image and flash the mawaqit.xz system image onto your Raspberry Pi’s SD card.
There are then two options: connected and offline. If you set yourself up using the connected option, you’ll be able to remotely control the app from your smartphone or any computer and tablet, which will be synchronised across all the screens connected to Raspberry Pi. You can also send messages and announcements. The latest updates from Mawaqit will install automatically.
If you need to choose the offline option and you’re not able to use the internet at your mosque, it’s important to equip your Raspberry Pi with RTC, because Raspberry Pi can’t keep time by itself.
All the software, bits of command line code, and step-by-step guidance you’ll need are available on this web page.
The Mawaqit project is free of charge, and the makers actually prohibit harnessing it for any monetary gain. The makers even created an API for you to create your own extentions — how great is that? So, if you want your own prayer clock for in a mosque, school, or just at home, take a look at Mawaqit.net.
The post Raspberry Pi prayer reminder clock appeared first on Raspberry Pi.
Dans le cadre d'un de ces programmes, les clients qui commandent des gadgets ou des équipements de gym risquent d'avoir une mauvaise surprise: ils reçoivent à la place des masques jetables.
L'article Le FBI met en garde contre la croissance des arnaques de faux commerces en ligne a d'abord été publié sur WeLiveSecurity
Do you know young people who dream of sending something to space? You can help them make that dream a reality!
We’re calling on educators, club leaders, and parents to inspire young people to develop their digital skills by participating in this year’s European Astro Pi Challenge.
The European Astro Pi Challenge, which we run in collaboration with the European Space Agency, gives young people in 26 countries* the opportunity to write their own computer programs and run them on two special Raspberry Pi units — called Astro Pis! — on board the International Space Station (ISS).
This year’s Astro Pi ambassador is ESA astronaut Thomas Pesquet. Thomas will accompany our Astro Pis on the ISS and oversee young people’s programs while they run.
And the young people need your support to take part in the Astro Pi Challenge!
The Astro Pi Challenge is back and better than ever, with a brand-new website, a cool new look, and the chance for more young people to get involved.
During the last challenge, a record 6558 Astro Pi programs from over 17,000 young people ran on the ISS, and we want even more young people to take part in our new 2020/21 challenge.
So whether your children or learners are complete beginners to programming or have experience of Python coding, we’d love for them to take part!
You and your young people have two Astro Pi missions to choose from: Mission Zero and Mission Space Lab.
In Mission Zero, young people write a simple program to take a humidity reading onboard the ISS and communicate it to the astronauts with a personalised message, which will be displayed for 30 seconds.
Mission Zero is designed for beginners and younger participants up to 14 years old. Young people can complete Mission Zero online in about an hour following a step-by-step guide. Taking part doesn’t require any previous coding experience or specific hardware.
All Mission Zero participants who follow the simple challenge rules are guaranteed to have their programs run aboard the ISS in 2021.
All you need to do is support the young people to submit their programs!
Mission Zero is a perfect activity for beginners to digital making and Python programming, whether they’re young people at home or in coding clubs, or groups of students or club participants.
We have made some exciting changes to this year’s Mission Zero challenge:
You have until 19 March 2021 to support your young people to submit their Mission Zero programs!
In Mission Space Lab, teams of young people design and program a scientific experiment to run for 3 hours onboard the ISS.
Mission Space Lab is aimed at more experienced or older participants up to 19 years old, and it takes place in 4 phases over the course of 8 months.
Your role in Mission Space Lab is to mentor a team of participants while they design and write a program for a scientific experiment that increases our understanding of either life on Earth or life in space.
The best experiments will be deployed to the ISS, and teams will have the opportunity to analyse their experimental data and report on their results.
You have until 23 October 2020 to register your team and their experiment idea.
To see the kind of experiments young people have run on the ISS, check out our blog post congratulating the Mission Space Lab 2019/20 winners!
To find out more about taking part in the European Astro Pi Challenge 2020/21, head over to our new and improved astro-pi.org website.
There, you’ll find everything you need to get started on sending young people’s computer program to space!
* ESA Member States in 2020: Austria, Belgium, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Luxembourg, the Netherlands, Norway, Poland, Portugal, Romania, Spain, Sweden, Switzerland, Latvia, and the United Kingdom. Other participating states: Canada, Latvia, Slovenia, Malta.
The post How young people can run their computer programs in space with Astro Pi appeared first on Raspberry Pi.
We’ve been following the work of Dominique Laloux since he first got in touch with us in May 2013 ahead of leaving to spend a year in Togo. 75% of teachers in the region where he would be working had never used a computer before 2012, so he saw an opportunity to introduce Raspberry Pi and get some training set up.
We were so pleased to receive another update this year about Dominique and his Togolese team’s work. This has grown to become INITIC, a non-profit organisation that works to install low cost, low power consumption, low maintenance computer rooms in rural schools in Togo. The idea for the acronym came from the organisation’s focus on the INItiation of young people to ICT (TIC in French).
INITIC’s first computer room was installed in Tokpli, Togo, way back in 2012. It was a small room (see the photo on the left below) donated by an agricultural association and renovated by a team of villagers.
Fast forward to 2018, and INTIC had secured its own building (photo on the right above). It has a dedicated a Raspberry Pi Room, as well as a multipurpose room and another small technical room. Young people from local schools, as well as those in neighbouring villages, have access to the facilities.
The first dedicated Raspberry Pi Room in Togo was at the Collège (secondary school) in the town of Kuma Adamé. It was equipped with 21 first-generation Raspberry Pis, which stood up impressively against humid and dusty conditions.
In 2019, Kpodzi High School also got its own Raspberry Pi Room, equipped with 22 Raspberry Pi workstations. Once the projector, laser printer, and scanners are in place, the space will also be used for electronics, Arduino, and programming workshops.
Now we find ourselves in 2020 and INTIC is still growing. Young people in the bountiful, but inaccessible, village of Danyi Dzogbégan now have access to 20 Raspberry Pi workstations (plus one for the teacher). They have been using them for learning since January this year.
We can’t wait to see what Dominique and his team have up their sleeve next. You can help INTIC reach more young people in rural Togo by donating computer equipment, by helping teachers get lesson materials together, or through a volunteer stay at one of their facilities. Find out more here.
The post Raspberry Pi reaches more schools in rural Togo appeared first on Raspberry Pi.
Whenever you learn a new subject or skill, at some point you need to pick up the particular language that goes with that domain. And the only way to really feel comfortable with this language is to practice using it. It’s exactly the same when learning programming.
In our latest research seminar, we focused on how we educators and our students can talk about programming. The seminar presentation was given by our Chief Learning Officer, Dr Sue Sentance. She shared the work she and her collaborators have done to develop a research-based approach to teaching programming called PRIMM, and to work with teachers to investigate the effects of PRIMM on students.
As well as providing a structure for programming lessons, Sue’s research on PRIMM helps us think about ways in which learners can investigate programs, start to understand how they work, and then gradually develop the language to talk about them themselves.
Sue began by taking us through the rich history of educational research into language and dialogue. This work has been heavily developed in science and mathematics education, as well as language and literacy.
In particular the work of Neil Mercer and colleagues has shown that students need guidance to develop and practice using language to reason, and that developing high-quality language improves understanding. The role of the teacher in this language development is vital.
Sue’s work draws on these insights to consider how language can be used to develop understanding in programming.
Sue identified shortcomings of some teaching approaches that are common in the computing classroom but may not be suitable for all beginners.
PRIMM was designed by Sue and her collaborators as a language-first approach where students begin not by writing code, but by reading it.
PRIMM stands for ‘Predict, Run, Investigate, Modify, Make’. In this approach, rather than copying code or writing programs from scratch, beginners instead start by focussing on reading working code.
In the Predict stage, the teacher provides learners with example code to read, discuss, and make output predictions about. Next, they run the code to see how the output compares to what they predicted. In the Investigate stage, the teacher sets activities for the learners to trace, annotate, explain, and talk about the code line by line, in order to help them understand what it does in detail.
In the seminar, Sue took us through a mini example of the stages of PRIMM where we predicted the output of Python Turtle code. You can follow along on the recording of the seminar to get the experience of what it feels like to work through this approach.
The PRIMM approach is informed by research, and it is also the subject of research by Sue and her collaborators. They’ve conducted two studies to measure the effectiveness of PRIMM: an initial pilot, and a larger mixed-methods study with 13 teachers and 493 students with a control group.
The larger study used a pre and post test, and found that the group who experienced a PRIMM approach performed better on the tests than the control group. The researchers also collected a wealth of qualitative feedback from teachers. The feedback suggested that the approach can help students to develop a language to express their understanding of programming, and that there was much more productive peer conversation in the PRIMM lessons (sometimes this meant less talk, but at a more advanced level).
The PRIMM structure also gave some teachers a greater capacity to talk about the process of teaching programming. It facilitated the discussion of teaching ideas and learning approaches for the teachers, as well as developing language approaches that students used to learn programming concepts.
The research results suggest that learners taught using PRIMM appear to be developing the language skills to talk coherently about their programming. The effectiveness of PRIMM is also evidenced by the number of teachers who have taken up the approach, building in their own activities and in some cases remixing the PRIMM terminology to develop their own take on a language-first approach to teaching programming.
Future research will investigate in detail how PRIMM encourages productive talk in the classroom, and will link the approach to other work on semantic waves. (For more on semantic waves in computing education, see this seminar by Jane Waite and this symposium talk by Paul Curzon.)
If you would like to try out PRIMM with your learners, use our free support materials:
If you missed the seminar, you can find the presentation slides alongside the recording of Sue’s talk on our seminars page.
In our next seminar on Tuesday 1 December at 17:00–18:30 GMT / 12:00–13:30 ET / 9:00–10:30 PT / 18:00–19:30 CEST. Dr David Weintrop from the University of Maryland will be presenting on the role of block-based programming in computer science education. To join, simply sign up with your name and email address.
Once you’ve signed up, we’ll email you the seminar meeting link and instructions for joining. If you attended this past seminar, the link remains the same.
The post PRIMM: encouraging talk in programming lessons appeared first on Raspberry Pi.
Des escrocs ciblent les utilisateurs de PayPal avec une nouvelle campagne de phishing par SMS qui tente de leur faire révéler des informations personnelles.
L'article Les utilisateurs de PayPal ciblés par une campagne de phishing via SMS a d'abord été publié sur WeLiveSecurity
Voici comment repérer les escroqueries dans lesquelles les criminels utilisent des SMS trompeurs pour accrocher leurs marques.
L'article Pourquoi tombons‑nous si facilement pour le phishing par SMS? a d'abord été publié sur WeLiveSecurity
Alors que les applications de rencontre connaissent un boom depuis le débuts de la pandémie de la COVID-19, les pertes dues aux arnaques amoureuses explosent également.
L'article Les arnaques romantiques en 2020 : Records de cœurs brisés et de portefeuilles volés a d'abord été publié sur WeLiveSecurity
Tout ce qui brille n'est pas de l'or - méfiez-vous aux faux témoignages de célébrités et autres arnaques qui ne sont pas près de se démoder.
L'article 4 arnaques courantes utilisant des célébrités pour attirer les victimes a d'abord été publié sur WeLiveSecurity
Voici comment votre numéro de téléphone peut être facilement volé, comment une attaque à l'échange de carte SIM réussie peut entraîner une kyrielle de problèmes et comment vous pouvez éviter d'en être une victime
L'article J’ai piraté le site Web de mon ami après une attaque de détournement de cartes SIM a d'abord été publié sur WeLiveSecurity
Des produits de marque contrefaits aux offres d'emploi trop belles pour être vraies, voici cinq stratagèmes courants utilisés par les fraudeurs pour soutirer aux adolescents leur argent et leurs données personnelles.
L'article Cinq arnaques courantes visant les adolescents et comment vous protéger a d'abord été publié sur WeLiveSecurity